伴随着HPC、自动驾驶、深度学习和VR/AR需求的不断增加,IO性能也在逐步凸显瓶颈,尤其是GPU与存储之间的读写。处理器速度已经从KHz进化至了GHz,VRAM从KB进化至了GB,IO速度也从KB/s进化至了GB/s,然而GB/s的大幅度改善从直观角度来看依然像是MB/s。
微软:Windows上的DirectStorage
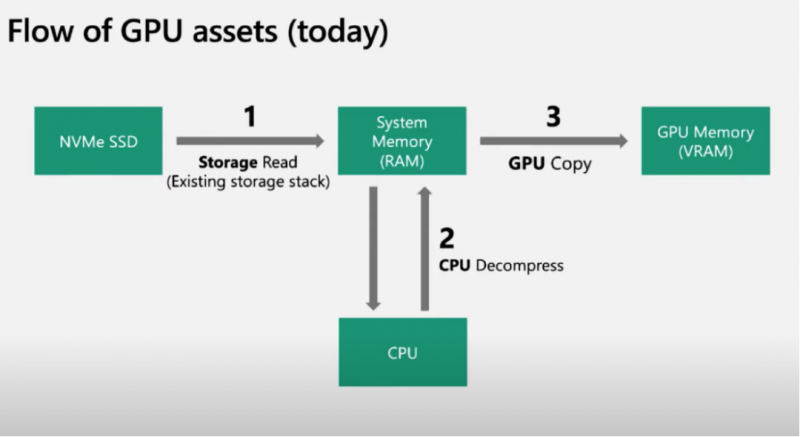
英伟达:RTX IO和Magnum IO GPUDirect Storage

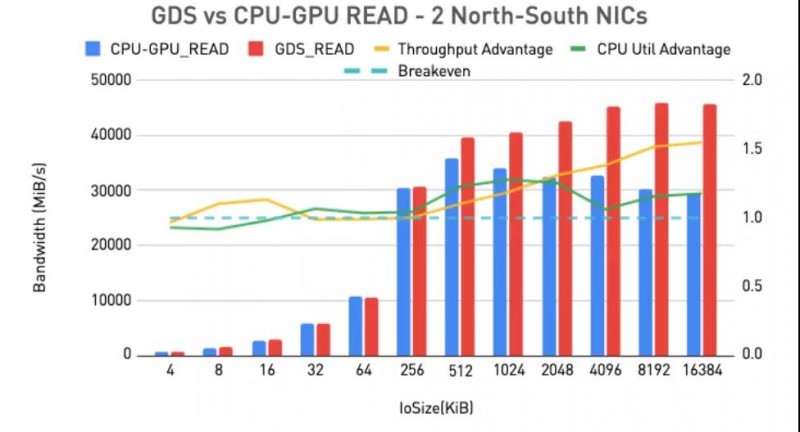
小结
微软:Windows上的DirectStorage
英伟达:RTX IO和Magnum IO GPUDirect Storage
小结