


ЁЁЁЁYoleГЦЃЌОЁЙм2022ФъШЋЧђЭЈеЭДѓЗљьЩ§ЃЌАыЕМЬхЪаГЁРњОжмЦкВЈЖЏЁЂашЧѓЕЭУдЕФОНОГЃЌЕЋЮЂПижЦЦїЃЈMCUЃЉЪаГЁдк2022ФъШдШЛХюВЊЗЂеЙЃЌзмЬхФъЪеШыдіГЄ25%ЁЃ
ЁЁЁЁ2023ФъРДЃЌаэЖрЙЉгІЩЬПЊЪМЕЃаФПтДцЙ§ЪЃЃЌвдМАЪмЕНЯћЗбЪаГЁжЇГіМБОчЯТНЕКЭЙЉгІЙ§ЪЃЕМжТЦНОљЯњЪлМлИёКЭЪеШыЯТНЕЕФбЯжигАЯьЃЌдЄМЦ2023ФъMCUЪаГЁШЋФъдіГЄНЋГжЦНЃЌЭЌЪБ2024ФъНЋБЃГжЕЭИіЮЛЪ§діГЄЃЌЕЋMCUЪаГЁЕФГЄЦкдіГЄЧБСІгШЦфРжЙл
ЁЁЁЁИљОнtechnavioБЈИцдЄМЦЃЌ2022Фъ-2027ФъМфЃЌMCUЪаГЁЙцФЃНЋвд6.97%ЕФИДКЯФъдіГЄТЪдіГЄЃЌЕН2027ФъЪаГЁЙцФЃдЄМЦНЋдіГЄ90.314вкУРдЊЁЃ
ЁЁ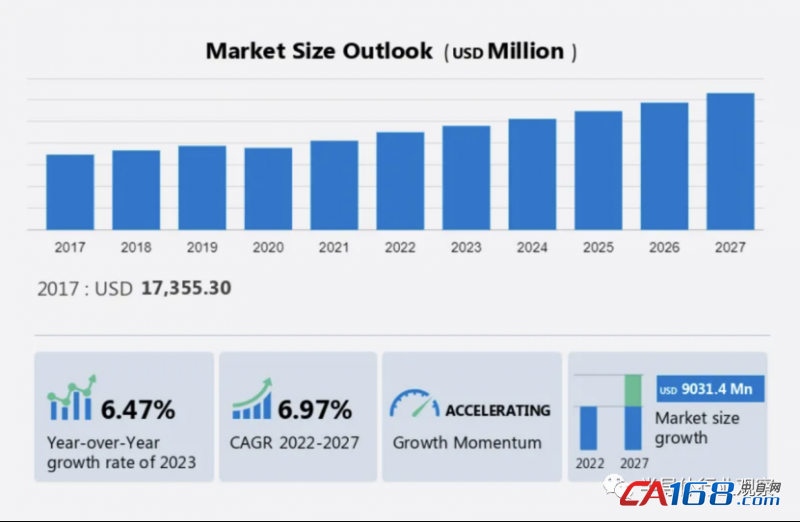
ЁЁЁЁЭМдДЃКtechnavio
ЁЁЁЁЪаГЁЕФдіГЄШЁОігкЖржжвђЫиЃЌАќРЈЦћГЕжаMCUЕФЪЙгУСПВЛЖЯдіМгЁЂЮяСЊЭјКЭжЧФмЩшБИЕФашЧѓВЛЖЯдіМгвдМАЯћЗбЕчзгаавЕЕФдіГЄЁЃ
ЁЁЁЁдкетИіЙ§ГЬжаЃЌЛЅСЊЩшБИЕФГжајдіГЄвдМАдкЮяСЊЭјБпдЕПЊЗЂИќЖржЧФмЩшБИЕФЧїЪЦЁЃЫцзХAIЩюШыЕНБпдЕКЭжеЖЫзАжУЃЌБпдЕМЦЫуЕФЗЂеЙГЩЮЊЭЦЖЏШЋЧђMCUЪаГЁдіГЄЕФжївЊЧїЪЦжЎвЛЁЃ
ЁЁЁЁетаЉЧїЪЦВЛНіЭЦЖЏСЫMCUЕФЪаГЁашЧѓЃЌвВдкДпЩњMCUаТЕФММЪѕИяаТЁЃ
ЁЁЁЁжкЫљжмжЊЃЌДЫЧАЕФAIдЫЫуКЭЛњЦїбЇЯАЕШжївЊдкдЦЖЫЭъГЩЃЌЯждке§дкж№НЅЯђБпдЕЖЫЗЂеЙЁЃБпдЕМЦЫуЪЧжИдкЭјТчБпдЕдЫааЕФМЦЫуЃЌИќППНќЪ§ОнЩњГЩдДЃЌЖјВЛЪЧЮЛгквЃдЖЕФЪ§ОнжааФЁЃетбљзіЕФКУДІдкгкЃЌФмМѕЩйдЦЖЫЩЯДЋЕФЪ§ОнДјПэЃЌЬсЩ§БОЕиЩшБИЕФЯьгІЫйЖШЃЌЬсИпБОЕиЪ§ОнЕФАВШЋадЁЃ
ЁЁЁЁЫцзХБпдЕМЦЫудкЮяСЊЭјСьгђВЛЖЯВПЪ№ЃЌMCUдкБпдЕМЦЫужаЕФЪЙгУНЋЛсдіМгЁЃгыДЫЭЌЪБЃЌдкЭђЮяЛЅСЊЕФЪБДњЃЌЪ§ОнГЪЯжБЌЗЂЪНЕФдіГЄЬЌЪЦЃЌCPUУцСйзХОоДѓЕФМЦЫубЙСІЁЃеыЖд“ШчКЮЪЭЗХCPUЕФМЦЫубЙСІ”ЃЌЪаУцЩЯвбОГіЯжВЛЭЌЕФНтОіЗНАИЁЃвЛаЉЦѓвЕПЊЪМдкMCUжаЬэМгМгЫйЦїЃЌЭЈЙ§зЈгУЫуСІРДНјааMLЕФдЫЫуЃЌвдЦкФмЪЭЗХCPUЕФЭЈгУЫуСІЁЃ
ЁЁЁЁМђЖјбджЎЃЌAIКЭMLЕФдЫЫуе§дкДгдЦЖЫЯђБпдЕЖЫЧЈвЦЃЌМЦЫужиаФЕФЧАжУПЩвдЬсИпБОЕиЕФЩшБИЯьгІЃЌМѕЩйдЦЖЫЩЯДЋЕФЪ§ОнДјПэЃЌЬсИпБОЕиЪ§ОнЕФАВШЋадЕШЃЌДјРДЕФКУДІВЛбдЖјгїЁЃЖјетжжБпдЕAIЃЌВЂВЛЛсжЙВНгкЪжЛњЁЂЕчФдетаЉОпБИSoCМЖБ№ЫуСІЕФжеЖЫЃЌЖјЪЧЛсМЬајЯђзХMCUЮЊжїПиЕФЮяСЊЭјЩшБИТћбгЁЃ
ЁЁЁЁЖдДЫЃЌMCUГЇЩЬЯрМЬНјааДДаТЃЌГЂЪдНЋAI/MLММЪѕМЏГЩЕНMCUжаЭЦЯђБпдЕЃЌвдИњЩЯИќжЧФмЕФБпдЕЩшБИЕФВНЗЅЃЌЕБЧАвбгавЛаЉЦѓвЕеЙПЊСЫЬНЫїВМОжЁЃ
ЁЁЁЁЭЗВПMCUДѓГЇЃЌЗзЗзЗЂСІ
ЁЁЁЁИљОнYoleЭГМЦЪ§ОнЃЌ2022ФъШЋЧђMCUГЇЩЬгЊЪеХХУћжаЃЌвтЗЈАыЕМЬхЃЈSTMЃЉЁЂгЂЗЩСшЃЈinfineonЃЉЁЂШ№ШјЕчзгЃЈRenesasЃЉЁЂЖїжЧЦжАыЕМЬхЃЈNXPЃЉЁЂЮЂаОПЦММЃЈMicrochipЃЉЮЛСаЧАЮхЃЌTop10ЦѓвЕЪаГЁЗнЖюКЯМЦеМБШИпДя93%ЁЃ
ЁЁ
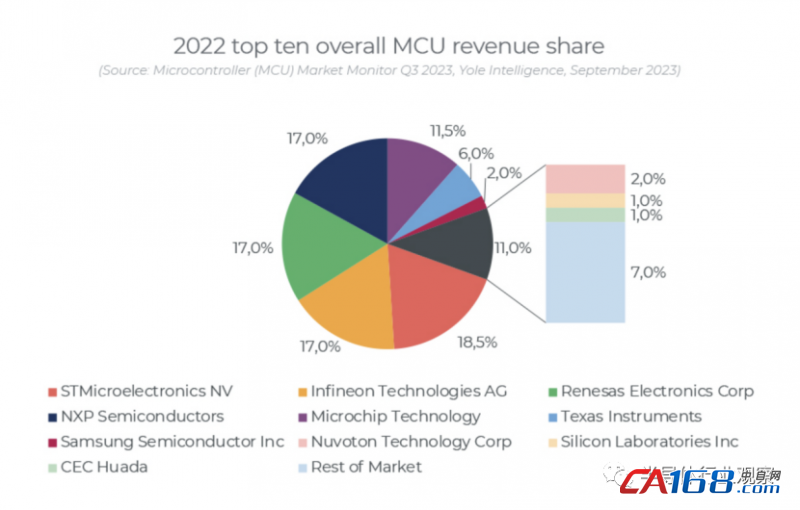
ЁЁЁЁБОЮФвдЭЗВПMCUГЇЩЬЮЊР§ЃЌеыЖдЩЯЪіБпдЕЩшБИЪаГЁЕФЗЂеЙЃЌРДПДвЛПДMCUаавЕе§дкШчКЮНјааДДаТгыбнБфЁЃ
ЁЁЁЁЖїжЧЦжЃКТЪЯШНЋNPUМЏГЩНјЭЈгУMCU
ЁЁЁЁЖїжЧЦждјБэЪОЃЌ“вдЧАЬсЕНКУMCUЕФБъзМОЭЪЧЃКАДЯТАДХЅОЭгаКмПьЕФЗДгІЃЌЕЋЯждкдЖВЛжЙетбљЃЌЮвУЧЯЃЭћДІРэЦїБОЩэгадЄжЊадЃЌетОЭашвЊв§ШыAIЕФвЊЫиЁЃЫљвдЯраХдНРДдНЖрЕФТфЕиЯюФПЛсвЊЧѓБпдЕМЦЫуЦНЬЈгЕгадНРДдНЖрЕФAIЙІФмжЇГжЁЃ”
ЁЁЁЁЪьЯЄЖїжЧЦжЕФШЫгІИУжЊЕРЃЌNXPгаШ§ДѓРрБпдЕМЦЫуЦНЬЈЃЌЗжБ№ЪЧЭЈгУMCUЦНЬЈЃЈLPCЁЂKinetisЃЉЃЌПчНчMCU iЃЎMX RTЯЕСаЃЌвдМАiЃЎMXКЭLayerscapeЯЕСагІгУДІРэЦїЃЌетШ§ДѓРрВњЦЗЙЙжўСЫNXPЙуРЋЖјЗсИЛЕФПЩЭиеЙЕФБпдЕМЦЫуЦНЬЈЁЃ
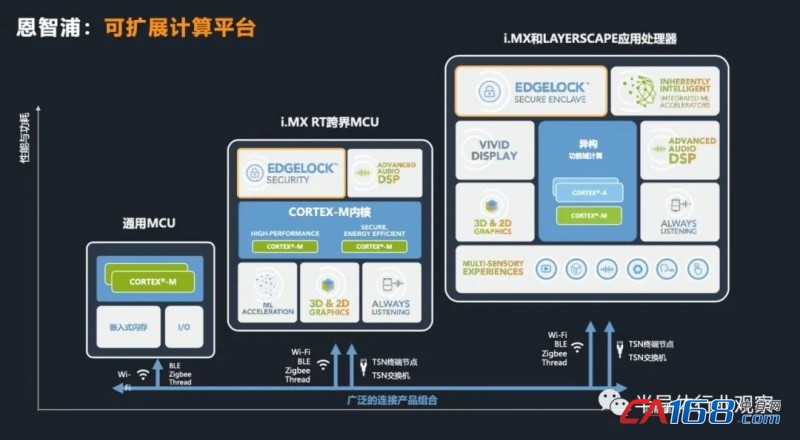
ЁЁЁЁНќФъРДЃЌЖїжЧЦжаТЭЦГіЕФПчНчMCUЬюВЙСЫMPUКЭMCUжЎМфЕФЪаГЁПеЯЖЃЌЛёЕУСЫНЯКУЕФЪаГЁЗДЯьЁЃ
ЁЁЁЁдкЭЈгУMCUЪаГЁЃЌвЛИіаТМЭдЊМДНЋПЊЦєЁЃОнIHSдЄВтЃЌ2030ФъНЋЛсга750вкИіСЊЭјЩшБИЃЌетДјРДСЫаТЕФMCUгІгУашЧѓЁЃЕЭЙІКФЁЂЮоЯпСЌНгЁЂАВШЋЁЂИпадФмКЭAIФмСІЕФзЗЧѓЃЌГЩЮЊСЫаТЕФЭЈгУMCUЕФБиБИФмСІЁЃЖјЧвЭЌвЛMCUЦНЬЈашвЊОпгаСщЛюЕФПЩЧЈвЦадЃЌЗНБуПЊЗЂепНјааЩшМЦЕФЧЈвЦЁЃ
ЁЁЁЁЛљгкжЧФмБпдЕЕФжжжжЧїЪЦЃЌNXPЭЦГіСЫЭЈгУMCUЦНЬЈ——MCXЮЂПижЦЦїВњЦЗзщКЯЁЃетвЛЦНЬЈШкКЯСЫLPCЁЂKinetisДЋЭГгХЪЦЃЌНЋПЊЦєЯТвЛЖЮжЧФмБпдЕЕФеїГЬЁЃ

ЁЁЁЁДЋЭГЩЯЃЌвЊНЋвЛаЉГЩЪьЕФЫуЗЈВПЪ№ЕНMCUЕФCPUКЫЩЯЃЌашвЊКФЗбДѓСПОЋСІЃЌЧвФбЖШНЯДѓЁЃФПЧАMCUГЇЩЬЖМгаЭЦГіЯргІЕФAIПЊЗЂЙЄОпАќЃЌЛђепЪЧР§ГЬЃЌЙЉПЊЗЂепЪЙгУЁЃ
ЁЁЁЁЕЋСэвЛИіЮЪЬтдкгкЃЌMCUЕФCPUКЫВЂВЛЪЪКЯзіAIКЭMLЕФдЫЫуЃЌетНЋЛсМЋДѓЕиеМгУЦфМЦЫузЪдДЁЃИпЖШвРРЕCPUКЫКЭFPUЕШгВМўзЪдДЃЌвВЛсДјРДЙІКФЕФЩЯЩ§ЃЌДгЯЕЭГНЧЖШРДПДВЂВЛЪЧКЯЪЪЕФзіЗЈЁЃ
ЁЁЁЁвђДЫЃЌдкЭЈгУMCUжаЬэМгвЛИігВМўNPUЃЌРДЮЊвЛаЉБпдЕВрЭЈгУЕФAIдЫЫуНјаазЈУХЕФМгЫйЃЌГЩЮЊСЫНтОіЮЪЬтЕФгХбЁЁЃCPUКЫПЩвдзЈзЂгкздМКЩУГЄЕФМЦЫуШЮЮёЃЌНЋAI MLЕФдЫЫуНЛИјNPUЁЃ
ЁЁЁЁЩЯЪіMCX NЯЕСаОЭЪЧШчДЫЃЌШУЪЪКЯЕФКЫШЅзіЪЪКЯЕФШЮЮёЃЌДгЖјАяжњПЊЗЂепЪЕЯжЮДРДжЧФмБпдЕИќКУЕФЩшМЦЁЃ
ЁЁЁЁОнНщЩмЃЌNPUзїЮЊCPUЕФAIдЫЫуаДІРэЦїЃЌЦфФкВПзюжївЊЪЧгЕгазЈУХЕФМЦЫуЭЈЕРЁЃИУNPUЮЊNXPЕФздбагВМўIPЃЌдкMCUСьгђжаЃЌМЏГЩЩёОДІРэЕЅдЊгІИУЫЕЪЧгКЯСЫетИіЪБДњЁЃ
ЁЁЁЁЮДРДЃЌИУNPUЛЙПЩвдРЉеЙЕНИќИпЕФадФмЛђИќаЁЕФЕЅдЊЁЃNXPЕФећИіMCUЁЂMPUМвзхРяЃЌЖМЛсВЩгУЭГвЛЕФNPUМмЙЙЃЌЬсЙЉИќИпадФмЕФNPUЕФМгЫйЦїЁЃЭЈЙ§вЛжТЕФNPUМмЙЙЃЌЭЌбљЕФЫуЗЈвВИќШнвзДгMPUЧЈвЦЕНMCUЦНЬЈЩЯЁЃ
ЁЁЁЁЯрБШвЛаЉAI SoCЃЌNXP NЯЕСаВњЦЗЕФЭЈгУадИќКУЃЌФмЙЛИВИЧЕНИќЖрЛљДЁгІгУЕФAIЬиадЩ§МЖЃЛЖјЖдгквЛаЉAIИќМгЧАжУЁЂдкДЋИаЦїжаЬэМгМгЫйЦїЕФВњЦЗЖјбдЃЌЦфМгЫйЦїЭљЭљЙІФмБШНЯЕЅвЛЃЌНіЪЪгУгкЦфДЋИаЦїЕФЪ§ОнЩИбЁЃЌВЂВЛОпБИИќСщЛюЕФЭЈгУадЃЌВЛФмжЇГжИќЖрЫуЗЈФЃаЭЁЃ
ЁЁЁЁНќШеЃЌЖїжЧЦжзюаТаћВМгыAptos-Eta ComputeНЈСЂКЯзїЛяАщЙиЯЕЃЌНЋЖїжЧЦжЯШНјЕФвдШЫЙЄжЧФмЮЊКЫаФЕФаОЦЌКЭШэМўЙЄОпМЏГЩЕНAptosЙЋЫОСьЯШЕФMLOpsЦНЬЈЩЯЁЃ
ЁЁЁЁдкДЫЙ§ГЬжаЃЌAptosПЩвдеыЖдИУаОЦЌгХЛЏКЭЕїећШЫЙЄжЧФмФЃаЭЃЌДгЖјЪЕЯжЧАЫљЮДгаЕФФЃаЭаЇТЪКЭадФмЃЌМђЛЏЕЭЙІКФБпдЕДІРэЦїЕФФЃаЭПЊЗЂЁЂВПЪ№КЭЙмРэЁЃ
ЁЁЁЁетДЮКЯзїБъжОзХдкЫѕаЁAIКЭЧЖШыЪНЯЕЭГжЎМфЕФВюОрЗНУцТѕГіСЫживЊвЛВНЁЃAptosЮоашИДдгЕиСЫНтаОЦЌЕФОпЬхЙІФмКЭЯожЦЬѕМўЃЌДгЖјЮЊЛњЦїбЇЯАПЊЗЂШЫдБКЭЧЖШыЪНЯЕЭГЙЄГЬЪІЬсЙЉСЫЧПДѓЕФжЇГжЁЃШЫЙЄжЧФмПЊЗЂШЫдБЯждкПЩвдЧсЫЩДДНЈКЭВПЪ№гХЛЏЕФЛњЦїбЇЯАФЃаЭЃЌГфЗжРћгУЖїжЧЦжаОЦЌЕФЧПДѓЙІФмЃЌЮоашЩюШыСЫНтЧЖШыЪНММЪѕЃЌМДПЩЙмРэЦЌЩЯФкДцКЭЕЭЙІКФЕШНєеХзЪдДЁЃЧЖШыЪНЯЕЭГЙЄГЬЪІПЩвдЪЙгУЮоДњТыЙЄОпСДЧсЫЩЛёЕУзюМбЕФAlФЃаЭЁЃетжж“МђЛЏ+гХЛЏ”ЪЧЪЙEdge AlИяУќГЩЮЊЯжЪЕЕФКЫаФЃЌЪЙЦфБШвдЭљШЮКЮЪБКђЖМИќШнвзЛёЕУКЭИпаЇ
ЁЁЁЁEta ComputeЙВЭЌДДАьШЫєпааЯњИБзмВУPaul WashkewiczБэЪОЃЌдкEdge AlПьЫйЗЂеЙЕФЪРНчжаЃЌазїЪЧГЩЙІЕФЙиМќЁЃEta ComputeКЭЖїжЧЦжАыЕМЬхЕФКЯзїБъжОзХвЕНчжТСІгкДђЦЦеЯАЃЌЮЊИќЖрСьгђЬсЙЉгааЇЕФНтОіЗНАИЃЌДгЖјЭЦЖЏБпдЕШЫЙЄжЧФмЕФЗЂеЙЁЃ
ЁЁЁЁОнЯЄЃЌMCXЕФгІгУГЁОАЪЧеыЖдMCUЯжгаЕФгІгУГЁОАНјааЕФЭиеЙЃЌдкДЋЭГЕФПижЦгІгУЛљДЁЩЯдіМгСЫдквНСЦЩшБИЁЂЮоШЫЛњЃЌЛђепЙЄвЕПижЦжаМгЩЯжЧФмЪЖБ№ЁЂЙЪеЯМьВтЁЂгявєПижЦЕШгІгУЁЃЛљгкNPUЕФГіЯжЃЌвВЛсбмЩњГіКмЖраТгІгУЃЌР§ШчдкШеГЃЩњЛюжаЪЖБ№ЮяЬхЕФГгЃЛвНбЇМьВтжаЃЌПЩвдгІгУгкМьВтКЌХБМВЕФКьЯИАћЃЛНЛЭЈГіаажаЃЌПЩвдАяжњжЧФмГЕЪЖБ№еЯАЃЌздЖЏЕизіГіХаЖЯКЭДІРэЕШЕШЁЃ
ЁЁЁЁећЬхРДПДЃЌИпадФмЁЂЮоЯпЁЂАВШЋКЭAIЬиадЃЌОпБИЫљгаетаЉЬиадЕФЭЈгУMCUЦНЬЈЪЧДѓЪЦЫљЧїЁЃвЕНчКмЖрГЇЩЬЦфЪЕвВвбОгаЗЧГЃЭъБИЕФЦНЬЈЃЌЕЋдкЭЈгУMCUжаЬэМггВМўNPUЃЌMCXЩаЪєЪзР§ЃЌПЩЮНЪЧNXPгжВЖзНЕНСЫвЛИіЙуРЋЧАОАЕФЪаГЁПеАзКЭЧхЮњЕФгІгУЧАОАЁЃ
ЁЁЁЁгЂЗЩСшЃКАхдиMLгВМўМгЫй
ЁЁЁЁНќШеЃЌгЂЗЩСшаћВМЭЦГіPSoC EdgeЯЕСаЮЂПижЦЦїЃЌЮЊБпдЕВйзїЛњЦїбЇЯА (ML) ЕФЩшБИЬсЙЉИпадФмКЭАВШЋадЁЃ
ЁЁЁЁPSoC EdgeЯЕСаMCUЬсЙЉФкжУMLжЇГжЁЂзджїФЃФтвдМАИќЖрЙІФмЃЌЪЙЦфГЩЮЊЯТвЛДњжЧФмБпдЕЩшБИЕФКђбЁепЁЃ
ЁЁ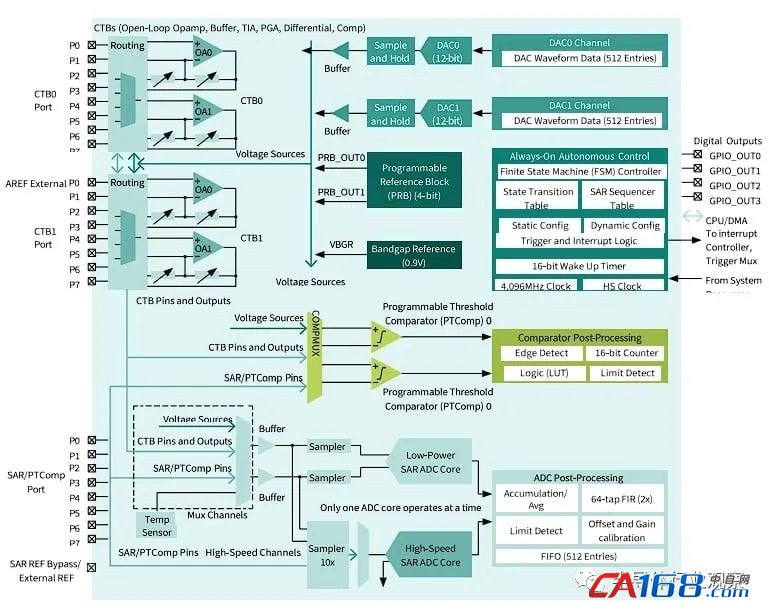
ЁЁЁЁPSoC Edge ЯЕСаMCUПђМм
ЁЁЁЁжЕЕУЙизЂЕФЪЧЃЌГ§СЫжЇГжCortex-M55 DSPКЭEthos-U55 NPUжЎЭтЃЌPSoC EdgeЯЕСаMCUЕФвЛИіЙиМќЙцИёЪЧАхдиMLгВМўМгЫйЃЌМЏГЩСЫгЂЗЩСшзЈгаЕФЩёОЭјТчгВМўМгЫйЦїNNLiteЁЃ
ЁЁЁЁетжжгВМўМгЫйЪЙИУЯЕСаMCUФмЙЛгУгкашвЊЯьгІМЦЫуКЭПижЦЕФИїжжгІгУЃЌАќРЈжЧФмМвОгЁЂПЩДЉДїЩшБИКЭШЫЛњНЛЛЅЩшМЦЁЃШЛЖјЃЌГ§СЫетаЉЬиЖЈСьгђжЎЭтЃЌЩшМЦШЫдБЛЙПЩвддкШЮКЮашвЊЦЌЩЯMLМгЫйЕФгІгУжаЪЙгУPSoC Edge MCUЁЃ
ЁЁЁЁвдЮяСЊЭјЩшБИЮЊР§ЃЌЛњЦїбЇЯАЙІФмПЩгУгкздЪЪгІЕигыЛЗОГНЛЛЅЃЌЖјЛњЦїШЫгУР§ПЩвдРћгУЛњЦїбЇЯАЙІФмРДЬсИпзджїЩшБИЕФаЇТЪКЭадФмЁЃЭЌЪБЃЌЫцзХЯђБпдЕЩшБИЗжХфИќЖрМЦЫуФмСІЕФЧїЪЦВЛЖЯЗЂеЙЃЌPSoC EdgeЯЕСаMCUЮЊгІгУЩшБИЬсЙЉСЫИќЖрЕФЙІФмКЭАВШЋадЁЃ ЫцзХдНРДдНЖрЕФПЊЗЂШЫдБЪЙгУИУаОЦЌЃЌЫћУЧПЩвдЦРЙРЦЌЩЯMLМгЫйКЭзджїФЃФтаХКХСДДјРДЕФадФмЬсЩ§ЁЃ
ЁЁЁЁСэЭтЃЌПЊЗЂЙЄОпвВЪЧгУЛЇдкПЊЗЂMCUЙ§ГЬжаБиВЛПЩЩйЕФвЛЛЗЁЃЮЊСЫИќКУЕФжЇГжAIЙІФмЕФПЊЗЂЃЌгЂЗЩСшЛЙЭЦГіСЫModusToolboxЛњЦїбЇЯАЙЄОпЃЌФмЙЛПьЫйЦРЙРMLФЃаЭВЂНЋЦфВПЪ№ЕНгЂЗЩСшMCUЩЯЁЃModusToolbox MLжМдкгыBSPЁЂСЌНгЖбеЛЁЂжаМфМўКЭгажБЙлЕФХфжУЦїЕФModusToolboxШэМўЩњЬЌЯЕЭГЮоЗьазїЃЌвдБуПЊЗЂШЫдБПЩвдзЈзЂгкЫћУЧЕФгІгУГЬађВювьЛЏВЂМгПьНјШыЪаГЁЁЃ
ЁЁЁЁДЫЭтЃЌЮЊжЇГжЦћГЕШЫЙЄжЧФмКЭГЕСОащФтЛЏЕФЧїЪЦЃЌгЂЗЩСшЛЙгыаТЫМПЦММКЯзїЭЦГіСЫеыЖдAIМгЫйЕФAurix TC4xЦНЬЈЃЌгЂЗЩСшЕФAURIX TC4x MCUМЏГЩСЫвЛИіИпадФмAIМгЫйЦїЃЌГЦЮЊВЂааДІРэЕЅдЊ (PPU)ЃЌгЩSynopsys DesignWare ARC EVДІРэЦїIPЬсЙЉжЇГжЁЃ
ЁЁЁЁдкAURIX TC4xМмЙЙжаМЏГЩЛљгкARC EVДІРэЦїЕФPPUЃЌЭЈЙ§ЬсЙЉОМУЪЕЛнЕФAIЪЕЯжСЫЙуЗКЕФЕчЖЏЦћГЕгУР§ЁЃPPUОпгаЪЕЪБДІРэадФмЃЌПЩМгЫйбЛЗЩёОЭјТчЁЂОэЛ§ЩёОЭјТчКЭЖрВуИажЊЦїЕШAIЫуЗЈЁЃГ§СЫЬсЙЉДІРэФмСІжЎЭтЃЌARC EV7xДІРэЦїIPЛЙЬсЙЉЙІФмАВШЋЬиадЃЌгыAURIXМмЙЙЯрНсКЯЃЌжЇГжПЊЗЂИќАВШЋЕФЦћГЕЯЕЭГЁЃ
ЁЁЁЁ2023Фъ5дТЃЌгЂЗЩСшаћВМвбЪеЙКзмВПЮЛгкШ№ЕфЫЙЕТИчЖћФІЕФГѕДДЙЋЫОImagimob ABЃЌвдЬсЩ§ЦфЮЂПижЦЦїКЭДЋИаЦїЩЯЕФTinyMLБпдЕAIЙІФмЁЃImagimobЪЧПьЫйдіГЄЕФЮЂаЭЛњЦїбЇЯАКЭздЖЏЛњЦїбЇЯАЃЈTinyMLКЭAutoMLЃЉЪаГЁЕФСьЯШепЁЃ
ЁЁЁЁSTЃКAIШэгВНсКЯЃЌИГФмMCU
ЁЁЁЁНќМИФъЃЌжЧФмМвЕчЕФПьЫйЗЂеЙЃЌЖдMCUЕФадФмЁЂЛЅСЊЬсГіСЫдНРДдНИпЕФвЊЧѓЃЌЛљгкMCUЦНЬЈдЫааШЫЙЄжЧФмКЭЛњЦїбЇЯАЃЌЗЂеЙадФмИќИпЁЂЙІКФИќЕЭЕФБпдЕМЦЫуЃЌе§дкГЩЮЊаавЕШШЕуЁЃУцЖдетбљЕФЧїЪЦЃЌвтЗЈАыЕМЬхКмдчОЭПЊЪМВМОжжЧФмЕФMCUЁЃ
ЁЁЁЁSTвбОДДНЈСЫвЛИіЦНЬЈЃЌЭЈЙ§STM32Cube-AIНЋMLгУгк32ЮЛMCU
ЁЁЁЁ2021Фъ6дТЃЌвтЗЈАыЕМЬхаћВМЪеЙКБпдЕAIШэМўзЈвЕПЊЗЂЙЋЫОCartesiamЃЌШУЛљгкArmЕФMCUОпгаЛњЦїбЇЯАКЭЭЦРэФмСІЁЃШЅФъЃЌSTЭЦГіСЫДјгаЩёОЭјТчгВМўДІРэЕЅдЊЕФЭЈгУЮЂПижЦЦї——STM32N6ЃЌетЪЧвтЗЈАыЕМЬхЕФЪзПюДјгаЩёОДІРэЕЅдЊгВМўМгЫйЦїЕФMCUЃЌНЋЭЦЖЏФПБъгІгУМЦЫуФмСІЕФЬсЩ§КЭЙІКФЁЂГЩБОЕФНјвЛВНЯТНЕЁЃгыЦфSTM32MP1ЮЂДІРэЦїЯрБШЃЌетПюMCUЕФЭЦЖЯЫйЖШЬсИпСЫ25БЖЁЃ
ЁЁЁЁОнСЫНтЃЌSTM32N6АќРЈвЛИізЈгаЕФNPUКЭвЛИіARM CortexФкКЫЃЌетЬсЙЉСЫгыХфБИAIМгЫйЦїЕФЫФКЫДІРэЦїЯрЭЌЕФAIадФмЃЌЕЋГЩБОНіЮЊЪЎЗжжЎвЛЃЌЙІКФНіЮЊЪЎЖўЗжжЎвЛЁЃ
ЁЁЁЁНёФъ5дТЃЌSTЭЦГіСЫЦфзюаТЕФ64ЮЛЮЂПижЦЦїSTM32MP2ЁЃЦОНшЖрИіARM CortexФкКЫЁЂвЛИіЩёОДІРэЕЅдЊЁЂвЛИіЭМаЮМгЫйЦїКЭЖрИіИпадФмI/OбЁЯюЃЌSTНЋаТДІРэЦїЖЈЮЛгкЙЄвЕ4.0гІгУжаЕФЛњЦїбЇЯАЁЃ
ЁЁЁЁДЫЭтЃЌвтЗЈАыЕМЬхЕФШэМўЙЄОпSTM32CubeMXжавВМЏГЩСЫAIФЃПщЃЌПЩвдЗНБуПЭЛЇНЋбЕСЗКУЕФAIФЃаЭзЊЛЛЮЊMCUЩЯдЫааЕФШэМўЃЌЪЙMCUПЩвдЗНБуЪЕЯжAIЙІФмЁЃ
ЁЁЁЁSTЛЙгЕгаSTM32Cube.AIКЭNanoEdge AI StudioШэМўЙЄОпЃЌВЂЧвгыNVIDIAКЯзїЃЌећКЯNIVIDIA TAOКЭSTM32Cube.AIЙЄОпЃЌШУПЊЗЂепдкSTM32ЮЂПижЦЦїЩЯЮоЗьЕибЕСЗКЭЪЕЯжЩёОЭјТчФЃаЭЁЃ
ЁЁЁЁЯрЖдРДЫЕЃЌСНИігХЪЦЛЅВЙЕФШэМўЙЄОпSTM32Cube.AIКЭNanoEdge AI StudioЃЌВњЦЗжжРрЗсИЛЕФSTM32ЮЂПижЦЦїКЭЮЂДІРэЦїЃЌвдМАДѓСПЕФДЋИаЦїВњЦЗзщКЯЃЌШУSTЕФШЫЙЄжЧФмНтОіЗНАИГЩЮЊЪаГЁЩЯБШНЯЗсИЛЕФШЫЙЄжЧФмВњЦЗзщКЯЁЃ
ЁЁЁЁШ№ШјЕчзгЃКвЕНчЪзПюM85ДІРэЦїMCU
ЁЁЁЁНќФъРДЃЌКмЖрГЇЩЬПЊЪМГЂЪддкMCUжаШкШыAIЙІФмЃЌШ№ШјЕчзгвВЪЧЙизЂMCU+AIЕФГЇЩЬжЎвЛЁЃ
ЁЁЁЁЫцзХЖдаЇТЪЁЂбгГйвдМАГЩБОЕФПМТЧЃЌЪаГЁПЊЪМГЂЪдВЩгУдНРДдНЖрЕФБпдЕМЦЫузїЮЊЧЖШыЪНЯЕЭГAI/MLЕФЪзбЁЗНАИЁЃ
ЁЁЁЁзїЮЊШЋЧђжївЊЕФMCUКЭMPUЙЉгІЩЬЃЌШ№ШјЕчзгЕФAIНтОіЗНАИЭЈЙ§ЪЙгУдкжеЖЫОпгажЧФмЪ§ОнДІРэФмСІЕФЧЖШыЪНAIММЪѕЃЌРДдіЧПвдаХЯЂКЭВйзїММЪѕЮЊЛљДЁЕФЯЕЭГКЭВњЦЗЁЃ
ЁЁЁЁдчдк2021ФъЃЌШ№ШјОЭЭЦГіУцЯђAIЕФСьЯШMPUВњЦЗЁЃШыУХМЖRZ/V2LЯЕСаОпБИЭЌРрЕФЕчдДаЇТЪКЭИпОЋЖШAIМгЫйЦїDRP-AIЃЌПЩНјааAIЭЦРэКЭЭМЯёДІРэЃЌвдЪЕЪЉИќОпГЩБОаЇвцЕФЪгОѕAIгІгУЁЃДЫЭтЃЌЭЈгУ64ЮЛRZ/G2LВњЦЗШКВЩгУзюаТArm Cortex-A55КЫаФЃЌгУгкИФНјAIДІРэЁЃ
ЁЁЁЁШЅФъЃЌШ№ШјЛЙЭЦГіСЫФкжУЪгОѕAIМгЫйЦїЕФRZ/V2MAЯЕСаВњЦЗЃЌНјвЛВНЪЕЯжСЫОЋШЗЭМЯёЪЖБ№КЭЖрЩуЯёЭЗЭМЯёжЇГжЙІФмЁЃ
ЁЁЁЁОнСЫНтЃЌRZ/V2ЯЕСаЪЧвЛжжФкжУШ№ШјЕчзгЖРМвгВМўМгЫйЦї “DRPЃЌЖЏЬЌПЩХфжУДІРэЦї-AI”ЕФAIзЈгУЮЂДІРэЦїЁЃDRP-AIзЈЮЊЧЖШыЪНЛњЦїЪгОѕРрAI/MLгІгУгХЛЏЩшМЦЃЌПЩЬсЙЉЪЕЪБAIЭЦРэКЭЭМЯёДІРэЙІФмЃЌЭЌЪБМцОпСЫИпAIЭЦРэадФмКЭЕЭЙІКФЬиадЃЌМвзхЛЏВњЦЗжЇГж0.4~80TOPSВЛЕШЕФПЩРЉеЙAIЫуСІЃЌЮЊзЪдДгаЯоЕФЧЖШыЪНЖЫВрAIгІгУЬсЙЉВювьЛЏгаОКељСІЕФНтОіЗНАИЁЃ
ЁЁЁЁШ№ШјБэЪОЃЌMCUгыMPUЕФМЦЫуаЇТЪКЭЪЕЪБДІРэAI/MLФЃаЭЕФФмСІВЛЖЯЬсИпЃЌЫцзХИїРргІгУЖдAI/MLММЪѕЕФЦеБщВЩгУЃЌMCUКЭMPUНЋМЬајдіМгAIМгЫйНсЙЙКЭNPUЁЃ
ЁЁЁЁНќШеЃЌШ№ШјЕчзгдйДЮЭЦГіЧПДѓЕФRA8ЯЕСаMCUЃЌаТаЭRA8ЯЕСаMCUВПЪ№СЫArm HeliumММЪѕЃЌМДArmЕФMаЭЯђСПРЉеЙЕЅдЊЁЃЯрБШЛљгкArm Cortex-M7ДІРэЦїЕФMCUЃЌИУММЪѕПЩНЋЪЕЯжЪ§зжаХКХДІРэЦїЃЈDSPЃЉКЭЛњЦїбЇЯАЃЈMLЃЉЕФадФмЬсИп4БЖЁЃ
ЁЁЁЁAIЕФГіЯждіМгСЫЖдБпдЕКЭжеЖЫжЧФмЕФашЧѓЃЌвдЗўЮёгкАќРЈЙЄвЕздЖЏЛЏЁЂжЧФмМвОгКЭвНСЦдкФкВЛЭЌЪаГЁЕФаТгІгУЁЃШ№ШјЕФаТаЭRA8ЯЕСаЮЊMCUЕФадФмКЭЙІФмЩшЖЈСЫаТЕФБъзМЃЌВЂНЋМђЛЏAIдкДѓСПаТгІгУжаЕФЪЕЪЉЃЌЖдгкЯЃЭћдкЧЖШыЪНКЭЮяСЊЭјСьгђАбЮеВЛЖЯдіГЄЕФAIЛњгіЧвМцЙЫАВШЋадЕФДДаТепРДЫЕЃЌЦфНЋИФБфгЮЯЗЙцдђЁЃ
ЁЁЁЁдкAIШэМўЗНУцЃЌШ№ШјЕчзгвВдкГжајЧПЛЏВМОжЁЃШ№ШјШЅФъжабЎЭъГЩЖдReality AIЕФЪеЙКЃЌПЩЮЊЦћГЕЁЂЙЄвЕКЭЯћЗбРрВњЦЗжаЕФИпМЖЗЧЪгОѕДЋИаЬсЙЉЧЖШыЪНAIКЭЮЂаЭЛњЦїбЇЯА(TinyML)НтОіЗНАИЁЃReality AIЕФЦьНЂReality AI ToolsЪЧвЛжжЮЊжЇГжећИіВњЦЗПЊЗЂЩњУќжмЦкЖјЙЙНЈЕФШэМўЛЗОГЃЌПЩЬсЙЉРДздЗЧЪгОѕДЋИаЦїЪ§ОнЕФЗжЮіЁЃ
ЁЁЁЁФПЧАЃЌReality AIЕФШЋЬзЙЄОпвбБЛгУгкжЇГжШ№ШјЫљгаЕФMCUКЭMPUВњЦЗЯпЃЌгУЛЇПЩРћгУИУЙЄОпЬззАШЅгХЛЏздМКЕФAIКЭMLФЃаЭЃЌЖдЭтЬсЙЉжЇГжAIдЫЫуЕФMCUЁЃ
ЁЁЁЁADIЃКгВМўCNNМЏГЩЃЌБпдЕAI MCUЕФММЪѕЧїЪЦ
ЁЁЁЁдкКмЖрДЙжБЕФБпдЕЖЫвЊЪЕЯжAIИГФмЃЌЕїгУдЦЖЫЕФAIФмСІЕФГЩБОНЯИпЃЌЖјЧвећИіСДЬѕЕФЯьгІЪБМфвВНЯГЄЃЌЖдгкСЌНгжЪСПЕФвРРЕГЬЖШвВНЯИпЃЌвђДЫВЂВЛФмзіЕННЯЮЊЪЕЪБЕФМЦЫуКЭДІРэЃЌетгыЖЫВрЕФЕЭЙІКФЁЂЕЭбгЪБЕФЯЕЭГЩшМЦФПБъВЂВЛЯрЗћЁЃ
ЁЁЁЁБпдЕAIТфЕиЃЌашвЊТњзуЖЫВрЕФЙІКФвЊЧѓЁЃ
ЁЁЁЁвђДЫЃЌФкжУгВМўCNNНјаазЈУХЕФAIдЫЫуЃЌГЩЮЊСЫADIдкAI MCUЩЯзюМббЁдёЁЃдкЖЫВрМЦЫуЕЅдЊжаВПЪ№вЛИізЪдДЙЛгУЕФОэЛ§ЩёОЭјТчЃЈCNNЃЉМгЫйЦїЃЌОЭПЩвдГаЕЃЦ№ЖЫВрЕФAIШЮЮёЃЌЖјЧввВЪЭЗХСЫИќЩУГЄзіМЦЫуШЮЮёЕФCPUЕШзЪдДЃЌДгЖјдкдіМгAIдЫЫуЕФЭЌЪБЃЌЛЙБЃжЄСЫДяЕНЖЫВрИпФмаЇФПБъЁЃ
ЁЁЁЁОнСЫНтЃЌдкАйвкIoTЩшБИжаЃЌДѓВПЗжЕФМЦЫуЕЅдЊЪЧMCUЁЃЖјдкMCUжаМЏГЩCNNМгЫйЦїЃЌвбОГЩЮЊСЫMCUЕФвЛИіЗЂеЙЗНЯђЁЃФПЧАжюЖрMCUГЇЩЬЖМвбОЭЦГіСЫAIМЏГЩЕФMCUВњЦЗЃЌADIвВЪЧШчДЫЁЃ
ЁЁЁЁОндЄВтЃЌ2025Фъ75%ЕФЪ§ОнВњЩњдкБпдЕВрНјааДІРэЃЌЖЫВрAI MCUЪаГЁЧБСІОоДѓЁЃ
ЁЁЁЁвдADIЭЦГіСЫБпдЕAIНтОіЗНАИMAX7800XЯЕСаMCUЮЊР§ЃЌMAX7800XЯЕСагЩСНИіЮЂПижЦЦїФкКЫЃЈARM Cortex M4FКЭRISC-VЃЉМгЩЯвЛИіОэЛ§ЩёОЭјТчЃЈCNNЃЉМгЫйЦїЙЙГЩЁЃетвЛМмЙЙеыЖдБпдЕAIгІгУНјааСЫИпЖШгХЛЏЃЌЪ§ОнЕФМгдиКЭЦєЖЏгЩЮЂПижЦЦїФкКЫИКд№ЃЌЖјAIЭЦРэгЩОэЛ§ЩёОЭјТчМгЫйЦїзЈУХИКд№ЁЃ
ЁЁЁЁОнСЫНтЃЌADIЕФБпдЕAIНтОіЗНАИОпБИЫйЖШПьЁЂЮоашЭтВПДцДЂЁЂЪБжгПижЦСщЛюКЭГЌЕЭЙІКФЕШЫФДѓЬиЩЋЃЌвђДЫЖдгкашвЊЪЙгУЕчГиЙЉЕчЁЂашвЊМАЪБОіВпЕФЮяСЊЭјЩшБИРДЫЕЬиБ№КЯЪЪЁЃ
ЁЁЁЁеыЖдБпдЕAIЕФМЦЫуЦНЬЈЃЌЯрНЯгкбЁдёFPGAЁЂGPUЁЂDSPЛђЦфЫќзЈгУASICЃЌЕЋADIЕФMAX7800XЦОНшзХеыЖдадЕФМмЙЙЩшМЦЃЌЬсЙЉСЫИќИпЕФФмаЇКЭадФмБэЯжЁЃ
ЁЁЁЁЖдБШДЋЭГЕФMCU+DSPЕФЗНАИЃЌADIЕФMAX7800XЕФCNNМгЫйЦїПЩвдНЋЙІКФНЕЕЭ99%вдЩЯЃЌЖјЧвЫуЗЈдкCNNЩЯжДааЕФаЇТЪвВБШDSPЩЯИќИпЁЃЖдгкЕЅДПВЩгУЮЂПижЦЦїЕФЗНАИЃЌMAX7800XЕФCNNМгЫйЦїОпБИИќИпЕФЪ§ОнЭЬЭТСПЃЌПЩвдНЋЫйЖШЬсИп100БЖвдЩЯЃЛЖјЧвЪЭЗХСЫCPUЕФЙЄзїИКдиЃЌЪЙЦфзЈзЂгкИќЩУГЄЕФМЦЫуШЮЮёЁЃЖјЖдгкFPGAЕШЗНАИЃЌЫфШЛПЩвдДІРэИќИДдгЕФЯИНкЃЌЕЋЦфГЩБОЁЂЙІКФКЭУцЛ§ЖМВЂВЛЪЪКЯИќБпдЕВрЕФВПЪ№ЃЌMAX7800XвВОпБИИќДѓЕФгХЪЦЁЃ
ЁЁЁЁЫцзХAIдкБпдЕЕФТфЕиЃЌгВМўCNNдкЖЫВрMCUЕФМЏГЩвбОГЩЮЊвЛжжММЪѕЧїЪЦЁЃетжжAI MCUЕФЗЂеЙНЋЛсгРДОоДѓЕФЪаГЁЛњгіЁЃ
ЁЁЁЁMCUГѕДДЙЋЫОЃКУщзМAIМгЫйЦї
ЁЁЁЁДЫЭтЃЌвЛаЉAIГѕДДЙЋЫОЃЌШчBrainchipЁЂHailoЁЂAlifвбОУщзМСЫAIМгЫйЦїЃЌПЩвдгУгкMCUгІгУЁЃвдAlifЮЊР§ЃЌ
ЁЁЁЁAlif SemiconductorЭЦГіЕФEnsembleЯЕСаШкКЯЮЂПижЦЦїЃЌ“ШкКЯ”СЫВЛЭЌЕФМЦЫуММЪѕ——ЪЕЪБMCUФкКЫЁЂЛњЦїбЇЯАМгЫйЦїКЭвЛаЉгІгУMPUФкКЫЃЌПЩвдгааЇДІРэЕчГиЙЉЕчЩшБИЩЯЗБжиЕФЛњЦїбЇЯАЙЄзїИКдиЁЃ
ЁЁЁЁОнЯЄЃЌЦфадФмБШЪЙгУИїжжAIФЃаЭжДааРрЫЦЙЄзїИКдиЕФДЋЭГ32ЮЛMCUИпГіСНИіЪ§СПМЖЁЃ
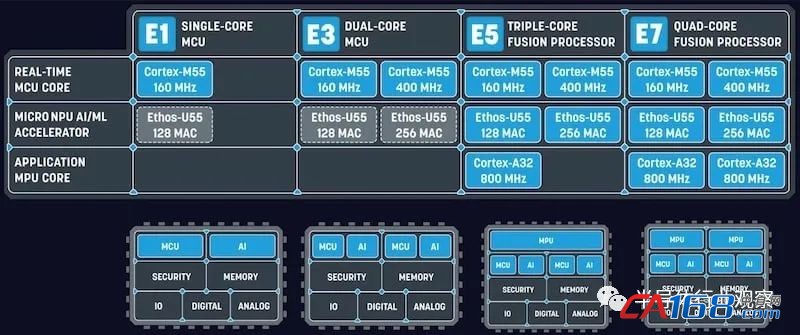
ЁЁЁЁAlif ЕФаТЯЕСа Ensemble ЮЂПижЦЦїКЭЮЂДІРэЦї
ЁЁЁЁЫцзХЯЕЭГЩшМЦШЫдБбАЧѓМѕЩйAI/MLДІРэЖддЦЕФвРРЕЃЌЯёEnsembleЯЕСаетбљЕФПЩРЉеЙБпдЕAIНтОіЗНАИПЩФмЛсдкЮДРДМИФъШЁЕУНјВНЁЃ
ЁЁЁЁArmЃКMCU+AIашЧѓЧПСв
ЁЁЁЁзїЮЊжкЖрMCUаОЦЌГЇЩЬЕФФкдкИГФмепЃЌArmНќФъРДСЌајЗЂВМСЫДјгаЫуСІЕФФкКЫMicroNPU Ethos U55ЁЂU65ЕШЯЕСаЃЌБъжОзХMCUЪаГЁЖдAIМгЫйЦїПЊЪМЬсГіИќЧПашЧѓЁЃ
ЁЁЁЁШчНёдкMCUжаМгШыAIМгЫйЦїж№НЅБфЕУСїааЦ№РДЃЌЪЙгУTiny ML/Embedded MLАбЫуЗЈВПЪ№дкMCUЩЯЃЌЛЙПЩвдИљОнВЛЭЌЕФгІгУГЁОАЧсЧЩСщЛюЕиВПЪ№дкВЛЭЌМмЙЙКЭзЪдДЕФЭЈгУMCUЩЯЁЃ
ЁЁЁЁArmдкЖЬЪБМфФкСЌајЗЂВМСНДњеыЖдMCUЕФmicroNPUЃЌвЛЗНУцЫЕУїMCUЪаГЁЖдгкAIКЭAIМгЫйЦїШЗЪЕгаКмЧПЕФашЧѓЃЛСэвЛЗНУцвВБэУїMCUКЭMPUЩѕжСCPUжЎМфЕФадФмВюОре§дкЫѕаЁЃЌетНЋЮЊЮДРДжЧФмMCUЩњЬЌДјРДаТЕФБфЛЏЁЃ
ЁЁЁЁAIКЭMCUЕФШкКЯЛђНЋНтЫјвЛИіХгДѓЕФЪаГЁЃЌЛђГЩЮЊЮДРДЭђЮяЛЅСЊЕФЛљЪЏЁЃ
ЁЁЁЁЭЌЪБвВПДЕНЃЌГ§СЫдкMCUжаМЏГЩгВМўМгЫйЦїЃЌдкMCUжаНтОіБпдЕAIЕФИќСїааЕФЧїЪЦдкгкЫуЗЈЕФЗЂеЙЃЌMLЫуЗЈПЩвдЪЙгУИќаЁЕФЙЄОпРДПЊЗЂЃЌШчTinyMLКЭTensorFlow LiteЃЌЪЙЦфФмЙЛдкMCUЕШЪмЯогВМўжаПЊЗЂAIгІгУЁЃ
ЁЁЁЁЩЯЪівВЬсЕНСЫШ№ШјЕчзгЁЂгЂЗЩСшЁЂSTЕШОљдкЗЂСІAIШэМўЗНАИЃЌШЅгХЛЏAIКЭMLФЃаЭЁЃЖдДЫЃЌMCUДѓГЇMicrochipЃЈЮЂаОПЦММЃЉвВдкВМОжЃЌЮЊСЫТњзуБпдЕЖЫЛњЦїбЇЯАПЊЗЂКЭЩшМЦашЧѓЃЌMicrochipвВЭЦГіСЫЭъећЕФМЏГЩЙЄзїСїГЬЃЌЭЈЙ§ЦфаТЕФMPLABЛњЦїбЇЯАПЊЗЂЬзМўРДМђЛЏMLФЃаЭПЊЗЂЁЃИУШэМўЙЄОпАќПЩдкMicrochipЕФMCUКЭMPUВњЦЗзщКЯжаЪЙгУЃЌвдПьЫйИпаЇЕиЬэМгMLЭЦРэЁЃ
ЁЁЁЁаДдкзюКѓ
ЁЁЁЁAIoTЪБДњЃЌAIЩюШыЕНБпдЕКЭжеЖЫзАжУЃЌвбОЪЧвЛИіГЄЦкБиШЛЕФДѓЗНЯђЁЃ
ЁЁЁЁЯрБШгкДЋЭГЗНЪНЃЌБпдЕAIЦОНшЖРЬигХЪЦФмЙЛИјИїаавЕЬсЙЉИќСюШЫТњвтЕФНтОіЗНАИЃЌдНРДдНЖрЕФШЫдкГЂЪдЪЙгУБпдЕAIРДНтОіаавЕЕФЭДЕуЮЪЬтЁЃ
ЁЁЁЁдкMCUжаМЏГЩгВМўМгЫйЦїЛђШкШыAIЫуЗЈЃЌПЩвдНЋMCUЕЭЙІКФЁЂЕЭГЩБОЁЂЪЕЪБадЁЂЮШЖЈадЁЂПЊЗЂжмЦкЖЬЁЂЙуРЋЕФЪаГЁИВИЧТЪЕШЬиадЃЌгыШЫЙЄжЧФмЧПДѓЕФДІРэФмСІЯрНсКЯЃЌДгЖјИќгаРћгкжеЖЫжЧФмЛЏЪаГЁЕФЗЂеЙЁЃ
ЁЁЁЁЛиЙЫаавЕРњГЬЃЌДѓИХзд2017ФъПЊЪМЃЌMCUГЇЩЬГЂЪддкMCUжаЬэМгAIЙІФмЁЃР§ШчЃЌSTЕФProject OrlandoЯюФПзїЮЊЪЕбщаджЪЕФMCUГЌЕЭЙІКФAIМгЫйЦїЕЅдЊЃЌШ№Шјдк2018ФъЗЂВМСЫеыЖдMCUЕФПЩБрГЬПЩжиЙЙаДІРэЦїDRPЁЃ
ЁЁЁЁжСНёЃЌОЙ§ЖрФъЗЂеЙЃЌдкMCUжаМгШыAIМгЫйЦїе§дкБфЕУдНРДдНжїСїЁЃ
ЁЁЁЁНЋAIФмСІМЏГЩЕНMCUЩЯЃЌЪЙЕУAIЫуЗЈПЩвдЪЕЪБЕидкЩшБИБОЕиНјааДІРэКЭЯьгІЃЌЖјЮоашвРРЕгкдЦЖЫЛђЦфЫћдЖГЬЗўЮёЦїЁЃетЬсИпСЫЯЕЭГЕФЪЕЪБадКЭМДЪБЯьгІФмСІЃЌЪЙЕУЩшБИФмЙЛИќПьЫйЕизіГіОіВпКЭЗДгІЃЌЧвПЩвддкЕЭЙІКФЕФЧщПіЯТЪЕЯжИпаЇЕФAIМЦЫуЁЃ
ЁЁЁЁЕБMCUЪаГЁПЊЪМгЕБЇAIЃЌвЛИіШЋаТЕФAIoTОжУцМДНЋПЊЦєЁЃдкЯТвЛВЈАйвкЮяСЊЩшБИЕФБГКѓЃЌMCUаавЕНЋгРДаТЕФБфИягыжиЙЙЁЃ












