正如Nextplatform所说,X86 架构花了 15 年的时间才在数据中心计算中占据了可观的份额,而 Arm 架构花了大约 10 年的时间才获得了可以衡量的立足点。也许 RISC-V 架构可能只需要五年的时间就能做到同样的事情,因为超大规模企业和云构建者已经厌倦了无法比现在更多地控制自己的基础设施命运。
这无疑是 Tenstorrent、SiFive、Esperanto Technologies 和 Ventana Micro Systems 等公司所期待的事情。考虑到超大规模企业和云构建者控制自己的硬件和软件堆栈的能力和愿望,以及他们承认自己不必设计到晶体管的所有内容,我们认为构建Chiplet和许可 IP 的公司将会从这些数据中心巨头那里获得一些业务,以加快其服务器的设计周期。

早在 2022 年 12 月,在 X86 和 Arm 服务器芯片设计方面拥有丰富经验的 Ventana 联合创始人和工程师就透露了公司VEYRON V1服务器芯片设计。该处理器与当时的 X86 和 Arm 服务器芯片绝对具有竞争力。随着 Veyron V1 chiplet于今年下半年上市,并自去年起作为 FPGA 仿真器提供,您可能想知道为什么 Ventana 那么迫不及待地将Veyron V2 推向市场。
答案是,Ventana 必须与现场的新一轮 X86 和 Arm 服务器芯片竞争,并应寻求支持的超大规模企业和云构建商的要求,改变其 RISC-V 服务器设计的chiplet互连致力于创建 RISC-V 服务器芯片。
UCIe,Chiplet的必然选择
互连的转变是一种微妙但重要的转变。最初的 Veyron V1 设计已经进行了两年,Ventana 选择了当时用于chiplet互连的最佳选项,称为 Bunch of Wires,简称BoW,由开放计算项目中的开放域特定架构小组推动。这几乎是一个标准所能达到的开放程度,特别是考虑到 AmpereComputing、阿里巴巴、AMD、ARM、思科系统、戴尔、Eliyan、富达投资、高盛、谷歌、惠普企业、IBM、英特尔、联想、Meta微软、诺基亚、Nvidia、Rackspace、Seagate Technology、Ventana 和 Wiwynn 等平台都支持 BoW,并致力于制定快速、广泛且廉价的芯片间互连标准,以实现跨供应商和跨制程的混合chiplet集成的承诺。
但随后,英特尔于 2022 年 3 月推出了替代的通用 Chiplet Interconnect Express(或 UCI-Express)标准,本质上是增强了自己的高级接口总线,这是一种用于连接chiplet的免版税 PHY, 早于 2018 年就被公布了,远远领先于BoW。由于 IT 行业喜欢技术差异化和选择,而英特尔喜欢施加比 BoW 努力更多的控制,因此 UCI-Express 诞生了,就像 Compute Express Link(或 CXL)一样,标准是由英特尔制定的,用于放置内存PCI-Express 之上的语义,几乎被所有拥有跨 CPU 和加速器的一致性内存竞争方法的人所采用。UCI-Express 一开始就得到了先进半导体制造公司、AMD、Arm Holdings、英特尔、谷歌、Meta Platform、微软、高通、三星和台积电的认可。最初的 UCIe参与者中缺少 HPE、IBM 和 Nvidia ,但他们最终会回心转意。
Ventana 联合创始人兼首席执行官 Balaji Baktha 表示,在与 46 位关注 Veyron V1 和 V2 CPU 设计的当前和潜在客户交谈时,我们发现 UCI-Express 显然是chiplet互连的最佳选择。因此,该公司加速了 Veyron V2 的发布,其中包括大量 RISC-V 核心增强功能,因为它采用 UCI-Express 而不是 BoW 进行chiplet互连。
以下是 BoW、AIB 2.0 和 UCI-Express 1.1 互连的馈送和速度的比较,是由 Lei Shan 撰写的论文的补充,他曾在 IBM TJ Watson 研究中心从事互连硬件工作,现在服务于Arm 服务器芯片新贵 Ampere Computing:
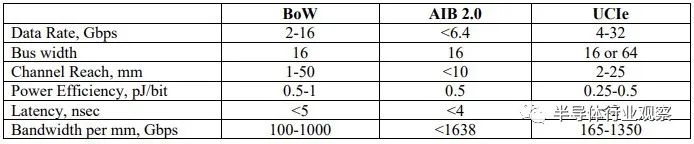
正如您所看到的,UCI-Express 的数据速率是 BoW 的 2 倍,而总线带宽可以相同或高出 4 倍。通道覆盖范围(channel reach )是 UCI-Express 距离的一半,但链路的能效提高了 2 倍,并且延迟不到 BoW 的一半。每毫米的带宽也高出 35% 到 65%。
“毫无疑问,如果芯片设计者想要使用chiplet,他们就必须支持 UCI-Express,”Baktha 告诉The Next Platform。“UCI_Express 背后有巨大的推动力和动力,因为每个人都想要一个标准。BoW 本来可以成为一个标准。但我们不想成为未来继续构建这一标准的人,因为 UCIe标准还有效地解决了封装成本,并且良率处于非常理想的水平。UCIe 还解决了 3D 内存堆叠问题。因此,很容易利用 UCI-Express 2.0 并利用我们自己的专业知识弥补 UCI-Express 1.0 存在的差距 - 例如,UCIe 根本不提供到 AMBA CHI 相干接口总线的链接,因此我们在 UCI 2.0 上添加了 AMBA 功能。”aktha 接着说。
抓住矢量扩展,走向RISC-V高性能
Ventana 希望快速抓住并融入其 Veyron V2 核心设计的另一项重大变化是 RISC-V Vector 1.0 512 位矢量扩展,该扩展类似于英特尔“Knights”Xeon Phi 处理器从 2015 年开始提供的扩展。这在一年前也刚刚添加到 AMD“Genoa”Epyc 处理器中。
这些 512 位向量引擎并不是字面意义上的 Intel AVX-512 的克隆(至少在软件层面上与 AMD Genoa 芯片中的引擎类似),但它们足够接近,不会为想要使用 AVX-512 的 Linux 开发人员将他们的代码从 X86 移植到 RISC-V带来一场完整的软件噩梦。此外,512 位向量将为 HPC 和 AI 工作负载提供与 X86 和 Arm 处理器竞争的性能,其中 CPU 将进行数学运算,而不是像 GPU 和其他加速器那样使用 CPU 封装上或 CPU 外部的加速器。
Ventana 为 V2 核心添加了扩展,使矢量引擎能够支持矩阵运算,并允许客户将自己的矩阵引擎添加到架构中,无论是在核心中还是在使用 UCI-Express 链路的离散chiplet中与其相邻。顺便说一句,V1 核心没有任何矢量引擎或矩阵引擎扩展,这显然会成为一个问题,因为大量 AI 推理仍在 CPU 上完成,并且在某些情况下 AI 训练和 HPC 模拟和建模是在 CPU 上完成的。也在CPU上完成。
Veyron V2 设计的另一个重大变化,就是我们一直在说的完整核心名称——以免与 Arm Ltd 在其 Neoverse CPU 设计中具有一对 256 位向量的“Demeter”V2 核心混淆。为此,Ventana创建了大幅改进的 RISC-V 内核。
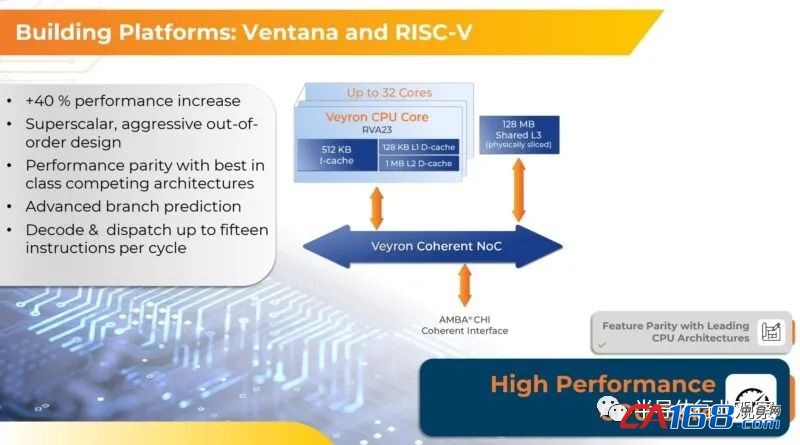
通过在 Veyron V2 核心中更积极地融合指令处理并进行大量其他调整,Ventana 已经能够将一揽子工作负载的每时钟指令数 (IPC) 提高 20%。V2 的高端时钟速度提升至 3.6 GHz,而 Veyron V1 核心的时钟速度也为 3 GHz,这意味着Ventana Veyron RISC-V CPU 设计中的 V1 内核到 V2 内核核心的性能再提升了 20%,从而使整体性能提升了 40%。。
Baktha 今天在 RISC-V Summit 2023 会议上发表了主题演讲,并透露了 Veyron V2 chiplet复合体的更多速度和馈送以及 Ventana 客户可以使用其知识产权和其他公司的知识产权创建的潜在 CPU 设计。
4nm工艺,最高支持192内核
Veyron V2 核心采用台积电的 4 纳米工艺设计,该工艺是我们今年早些时候讨论的Veyron V1 chiplet默认设计的 5 纳米工艺的缩小版。V2 内核支持 RVA23 架构配置文件,其中强制包含 512 位向量扩展。还有在向量引擎上运行的加密函数。
以下是基于 V2 的 CPU 在概念上的样子,其中包含一个 I/O 芯片和六个 32 核 V2 chiplet以及一些链接的特定领域加速器:

该图显示了 I/O 集线器与 PCI-Express 5.0 控制器和 DDR5 内存控制器的链接,但如果公司愿意的话,可以更换 HBM3 内存控制器。默认设计在六个 V2 chiplet上有 12 个 DDR5 内存控制器,或者在四个 V2 chiplet上有 8 个 DDR5 内存控制器,这与我们目前期望在任何服务器 CPU 中看到的平衡相同。
Ventana 的 V2 内核支持 RV64GC 规范,并实现了超标量(superscalar)、无序管道(out of order pipeline),每个时钟周期可以解码和调度(decode and dispatch)多达 15 条指令。得益于其 IOMMU 设计和高级中断架构 (AIA:Advanced Interrupt Architecture),V2 内核可以支持 Type 1 和 Type 2 服务器虚拟化管理程序(server virtualization hypervisors )以及嵌套虚拟化(nested virtualization)。
该内核还具有用于调试、跟踪和性能监控的端口。所有这些都是现代超大规模数据中心服务器 CPU 的赌注。V1 和 V2 核心都没有同时超线程(simultaneous hyperthreading),就像 Amazon Web Services 和 AmpereComputing 的 Arm 核心没有同时超线程一样,未来“Sierra Forest”Xeon SP 处理器中使用的未来“Sierra Glen”核心也不会具备这个功能。
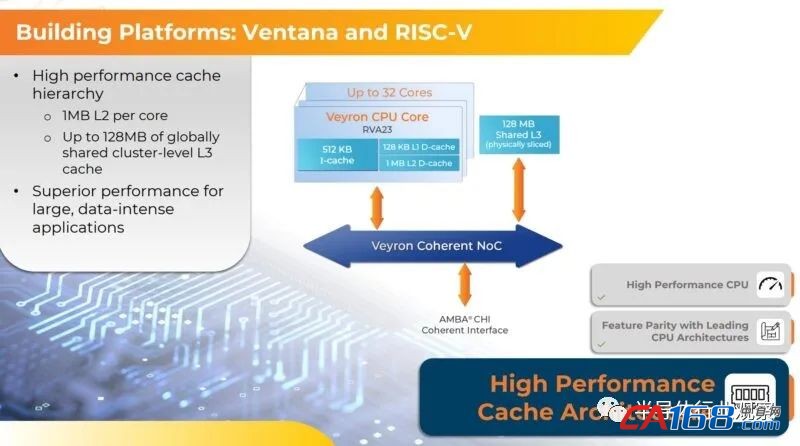
Veyron V2 核心拥有 512 KB 的 L1 指令缓存和 128 KB 的 L1 数据缓存以及 1 MB 的 L2 数据缓存。这些核心具有与其关联的 4 MB L3 缓存片( cache slice),并且在Veyron V2 chiplet复合体中的 32 个核心中,因此有 128 MB 的缓存。每个chiplet上的内核使用专有的片上相干网络网状互连相互链接,该网络为内核、内存和其他 I/O 提供 5 TB/秒的聚合带宽。
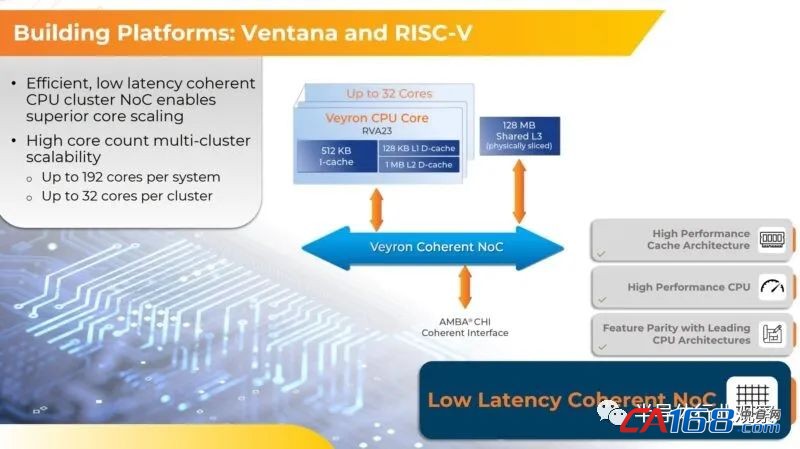
四个 V2 chiplet可以与 UCI-Express 互连,以创建 128 个核心复合体,如果您确实想突破极限,您可以将最多六个chiplet连接在一起,在单个Veyron插槽中获得 192 个核心。虽然其每个核心的性能可能无法达到 Zen 4c 水平,但它专注于 UCIe 和特定领域加速 (DSA),以提供更现代的计算平台。
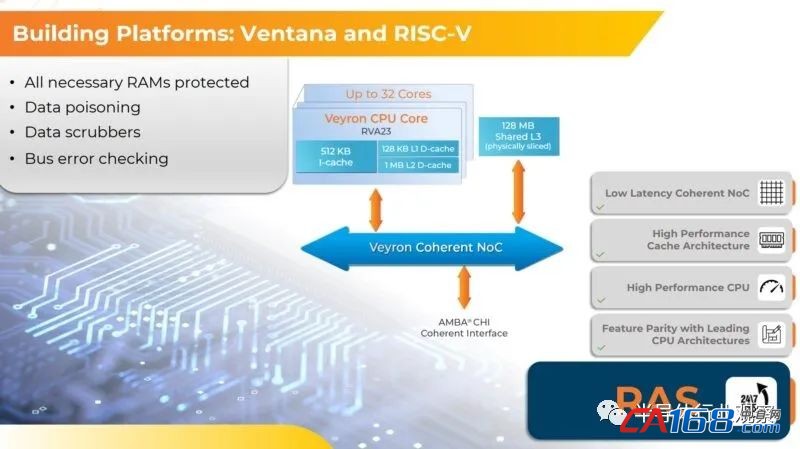
该芯片的另一大特点是RAS,具有ECC能力等。
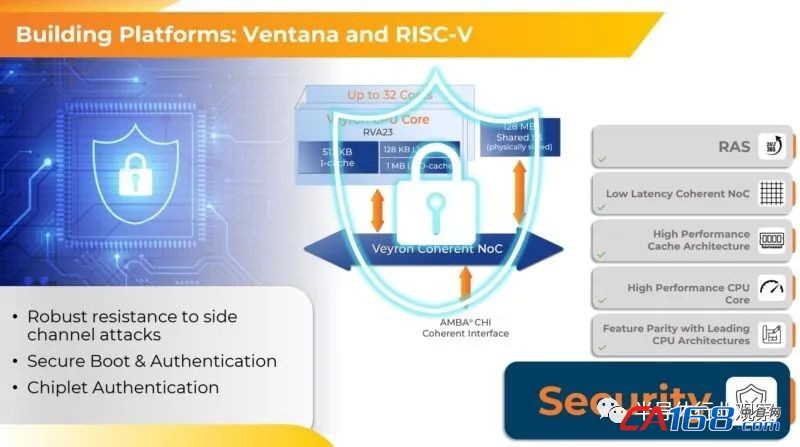
如今,数据中心处理器需要具有安全启动和身份验证。Chiplet CPU 还需要进行 Chiplet 身份验证。
如开头所说,Ventana 使用 UCIe 连接到具有 DDR 和 PCIe 控制器的 I/O 集线器。UCIe将成为行业的一股力量,这张图应该有助于解释原因。我们没有看到 Ventana 仅具有 CPU 核心计算chiplet。相反,这些幻灯片也都展示了特定领域的加速chiplet。
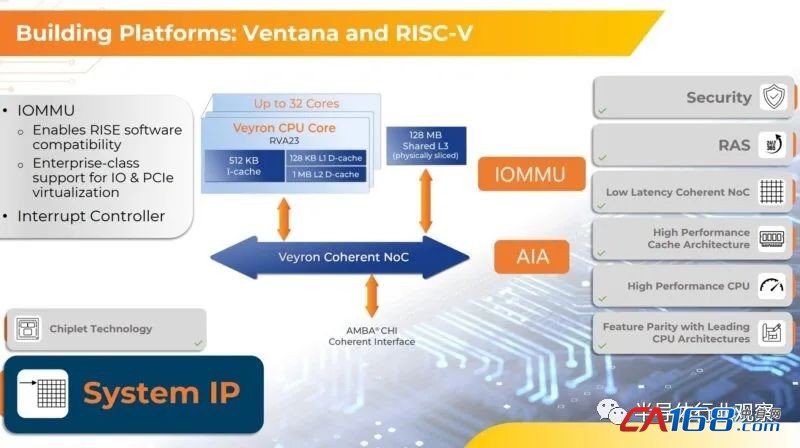
Ventana 也支持 RISE。RISC-V 有时被比作狂野西部,因为从理论上讲,人们可以用 CPU 做任何事情。Ventana 是一种 RISC-V 设计,但它希望成为一种基于标准的兼容性设计,因此 RISE 支持很重要。
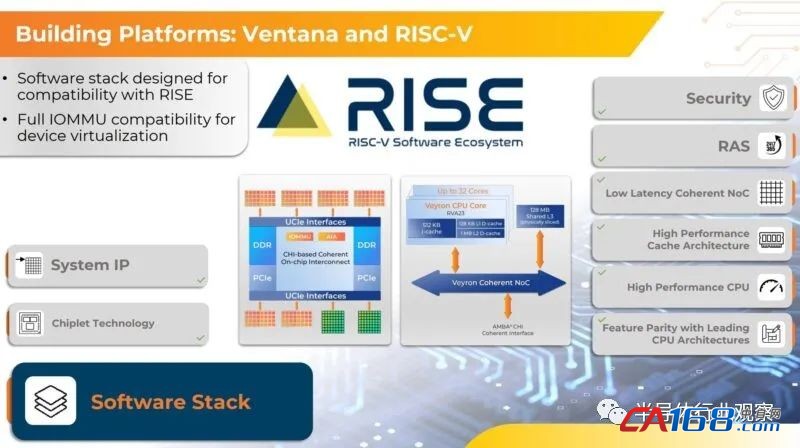
公平地说,Ventana 可以拥有很好的 RISC-V 部件,但在一代时间内比替代品快 5% 并不会让公司转向架构。相反,该公司寄希望于将加速chiplet(可能基于 UCIe)集成到 I/O 集线器中的想法,作为其战略的核心部分,从而赋予其部件不同的性能曲线。例如,在存储服务器中,加密和压缩的集成可能很重要。在 CDN 服务器中,这可能是一个转码加速器。我们的想法是,集成这些加速器会改变曲线。这已经是行业惯例,只是 AMD 以及 Ampere 和Intel 等公司将 PCIe 总线上的加速器直接集成到 CPU 中。

此时,32 核 UCIe 支持的chiplet有空间在封装上添加加速器chiplet的想法可能听起来令人兴奋,但还有更多。超缩放器(Hyper-scalers)希望将自定义加速直接添加到 I/O 中心。Ventana 已经在宣传其chiplet用于客户设计的 I/O 集线器。

chiplet方面非常有趣,因为它可以更快地制造芯片。可以添加 FPGA,然后添加 ASIC 加速器。这增加了灵活性,但也降低了进入门槛,因为它允许使用使用 UCIe 和 I/O 集线器的较小 IP 块来构建软件包。
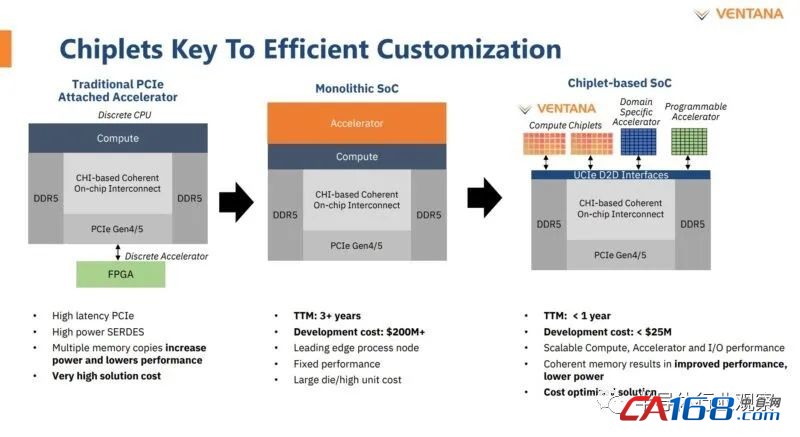
Ventana 的目标是让其客户设计使用这些 DSA chiplet(无论是 FPGA 还是 ASIC)来提供更好的工作负载效率,而不仅仅是最大 SPECint 吞吐量。

这是一些 DSA 块的一个很好的例子。这里真正好的一个是基础设施卸载。

在Ventana的演示最后,有一台服务器。这似乎是一个千兆字节平台,将是一个带有 12 通道 DDR5-5600 的单插槽 192 核 1U 服务器。不要过多关注实际图片,因为它似乎是一个 Intel Skylake/Cascade Lake 服务器,在 CPU 插槽区域周围有一点 Photoshop 的魔力。

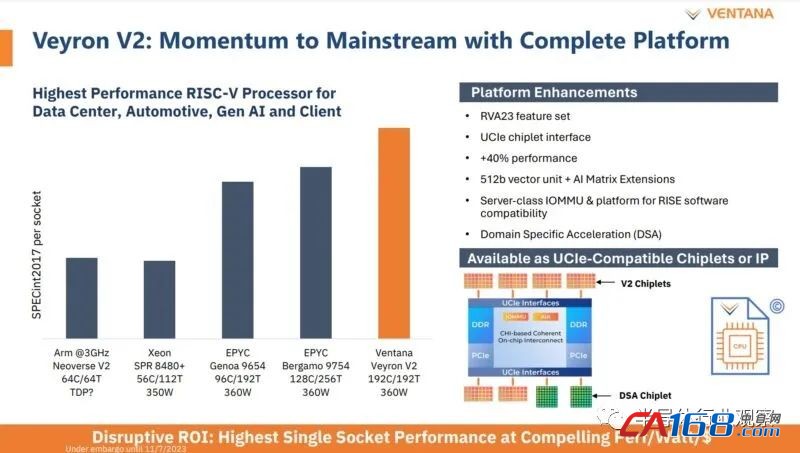
从 Ventana 模拟 Veyron V2 的整数性能以及每个插槽的原始 SPECint2017 速率后,我们可以看到以下结果:
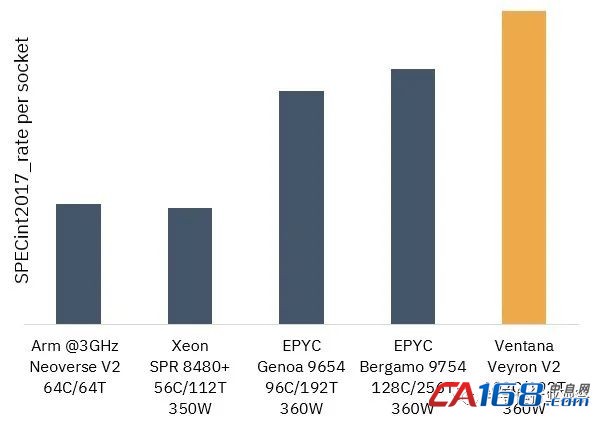
如果您对上图进行计算,那么在相同的 360 瓦功率下,具有 192 个内核的Veyron 2 RISC-V CPU 的整数吞吐量将比 AMD 的“Bergamo”Epyc 9754 处理器(具有 128 个内核和 256 个线程)高出约 23%在相同的 360 瓦热封装中,性能比 96 核“Genoa”Epyc 9654 高出约 34%。Veyron V2 芯片与 56 核“Sapphire Rapids”Xeon SP 8480+ 的性能差距更像是 2.7 倍,这并不奇怪,因为它拥有 3.4 倍的核心和 1.7 倍的线程,尽管事实上,V2 内核必须以较低的时钟速度运行。下降的 Arm 芯片看起来是 AWS Graviton3 的代表,后者拥有 64 个核心,性能比所示的 Sapphire Rapids 芯片稍高一些。
Ventana 提供基准 Veyron V2 设计,具有 4 个 128 个内核的chiplet和 8 个 DDR5 内存通道,chiplet上具有 UCI-Express 互连,并且有一个 I/O bug 将它们全部集成到服务器 CPU 插槽内。
从这个介绍看来,Ventana 确实是带来了不同的东西。如果你看看 Ampere 和之前 Marvell/Cavium 在服务器领域尝试做的事情,就会发现它们是在通用计算平台上与英特尔直接竞争,其中一项重大优化是将高级台积电工艺节点上的浮点吞吐量降低到获得更好的每瓦整数性能。这确实是当今 Arm 服务器的魔力。
Ventana 正在做一些不同的事情,希望成为 UCIe 时代的 CPU 核心,预计市场将加速发展。这感觉有点像 Annapurna Labs / AWS 模型,而不是一些著名的 Arm 玩家一直在做的事情。