


аЃЖдЃКЖЁдН гЂЗЩСшПЦММЯћЗбЁЂМЦЫугыЭЈбЖвЕЮёДѓжаЛЊЧј ЪзЯЏЙЄГЬЪІ
ЕМбд
дкгЂЗЩСшЃЌЮвУЧвЛжБМсаХзПдНЕФвєЦЕНтОіЗНАИЖдгкЬсЩ§ЯћЗбРрЩшБИЕФгУЛЇЬхбщжСЙиживЊЁЃЮвУЧМсЖЈВЛвЦЕижТСІгкДДаТЃЌдкжїЖЏНЕдыЁЂгявєЭИДЋЁЂТМвєЪвТМвєЁЂвєЦЕБфНЙКЭЦфЫћЯрЙиММЪѕЗНУцШЁЕУСЫЯджјНјВНЃЌЖдДЫЮвУЧЩюИаздКРЁЃзїЮЊMEMSТѓПЫЗчЕФСьЯШЙЉгІЩЬЃЌгЂЗЩСшМЏжазЪдДИФЩЦMEMSТѓПЫЗчЕФвєЦЕжЪСПЃЌЮЊTWSКЭЖњежЪНЖњЛњЁЂБЪМЧБОЕчФдЁЂЦНАхЕчФдЁЂЛсвщЯЕЭГЁЂжЧФмЪжЛњЁЂжЧФмвєЯфЁЂжњЬ§ЦїЩѕжСЦћГЕЕШИїжжЯћЗбЩшБИДјРДзПдНЬхбщЁЃ
НёЬьЃЌЮвУЧЩњЛюдквЛИіМЄЖЏШЫаФЕФЪБДњЃЌШЫЙЄжЧФме§дкГЙЕзИФБфШеГЃЩњЛюЃЌЖјChatGPTЕШЙЄОпе§дкЭЈЙ§жБЙлЕФЮФБОКЭгявєНЛЛЅжиаТЖЈвхЙЄзїаЇТЪЁЃЫцзХШЫЙЄжЧФмЯЕЭГЕФВЛЖЯНјВНЃЌДЋЭГЕФЩЬвЕФЃЪНЁЂаХбіКЭМйЩше§дкЪмЕНЬєеНЁЃгявєдкаТаЫЕФШЫЙЄжЧФмЩњЬЌЯЕЭГжаАчбнЪВУДНЧЩЋЃПзїЮЊЦѓвЕСьЕМепЃЌЮвУЧЪЧЗёашвЊжиаТЫМПМЮвУЧЕФаХФюЃП ЩњГЩЪНШЫЙЄжЧФмЕФаЫЦ№ЪЧЗёЛсНЕЕЭИпжЪСПгявєЪфШыЕФживЊадЃЌЛђепИпжЪСПгявєЪфШыЪЧЗёЛсГЩЮЊЙуЗКВЩгУШЫЙЄжЧФмЗўЮёКЭИіШЫжњРэЕФБивЊЬѕМўЃП
ШЫЙЄжЧФмЃЌДгЕУСІжњЪжЕНзюКУЕФХѓгб
ШЫРрВЛНіЛсИљОнЮЪЬтЕФФкШнЃЌвВЛсИљОнЬсЮЪЕФаЮЪНЕїећздМКЕФЛиД№ЃЌетЪЧКмздШЛЕФЪТЧщЁЃШЫРрЕФЩљвєЬсЙЉСЫИїжжЯпЫїЃЌПЩгУРДХаЖЯЬсЮЪепЕФФъСфЁЂадБ№ЁЂЩчЛсКЭЮФЛЏБГОАвдМАЧщаїзДЬЌЁЃДЫЭтЃЌЪЖБ№ЫљДІЕФЛЗОГЃЈШчЛњГЁЁЂАьЙЋЪвЁЂНЛЭЈЛђХмВНЕШЬхг§ЛюЖЏЃЉвВгажњгкШЗЖЈЬсЮЪепЕФвтЭМЃЌВЂЯргІЕиЕїећД№АИВЂИќКУЕФЖдЛАЁЃ
ОЁЙмШЫЙЄжЧФмЕФФмСІгаСЫГЄзуЕФНјВНЃЌЕЋШЫУЧШдШЛШЯЮЊЃЌЛљгкШЫЙЄжЧФмЕФИЈжњЙЄОпШБЗІе§ШЗдЄВтШЫРрЬсЮЪвтЭМЛђЬиЖЈаХЯЂНЋШчКЮБЛНтЖСЕФФмСІЁЃЮЊСЫИФЩЦШЫЛњНЛЛЅЃЌШЫЙЄжЧФмдкзіГіаоДЧбЁдёЪБгІПМТЧШ§ИіЙиМќвђЫиЃКЖдЬ§епЕФСЫНтЁЂЬ§епЕФЧщаїзДЬЌКЭЛЗОГБГОАЁЃ
дкаэЖрЧщПіЯТЃЌНіЦОНгЪеЕНЕФвєЦЕаХКХОЭзувдЬсШЁгагУЕФаХЯЂВЂзіГіЪЪЕБЕФЗДгІЁЃР§ШчЃЌПМТЧвЛЯТгыЫиЮДФБУцЕФШЫНјааЕчЛАЛђвєЦЕЛсвщЕФЧщПіЁЃИќживЊЕФЪЧЃЌПМТЧвЛЯТдкУЛгаЛњЛсЕБУцНЛСїЕФЧщПіЯТЃЌвЛИіШЫдкЗДИДНЛЬИКѓЖдСэвЛИіШЫЕФИажЊЪЧШчКЮЗЂеЙКЭБфЛЏЕФЁЃ
зюНќЕФбаОПБэУїЃЌМДЪЙШЫЙЄжЧФмЕФгябдЗДгІЗчИёЗЂЩњЮЂаЁЕФБфЛЏЃЌвВЛсЕМжТШЫЙЄжЧФмЕФЩчНЛФмСІКЭИіадЗЂЩњУїЯдБфЛЏЁЃЮвУЧгаРэгЩМйЩшЃЌдкЪЪЕБЕФЩљвєЪфШыЫЎЦНЯТЃЌЮДРДЕФШЫЙЄжЧФмЯЕЭГНЋФмЙЛзїЮЊгааЇЕФЛяАщЗЂЛгзїгУЃЌБэЯжГіШЫРрХѓгбЕФааЮЊЃЌР§ШчбЏЮЪВЂеце§ЧуЬ§Д№АИЃЌЛђепжЛЪЧЧуЬ§ВЂдкЪЪЕБЕФЪБКђБЃСєХаЖЯЁЃ
ШЫРрШчКЮЬхбщвєЦЕаХКХЃП
гыШЮКЮгябдНЛСївЛбљЃЌвєЦЕаХЯЂвВЪЙгУгябдКЭЮФзжРДДЋДяЫМЯыЁЂЧщИаКЭЙлЕуЁЃДЫЭтЃЌвєЕїЁЂЫйЖШЁЂвєСПКЭБГОАдывєЕШЦфЫћНЛСїдЊЫивВЛсгАЯьЖдаХЯЂЕФећЬхИажЊЁЃ
ДгПЦбЇЕФНЧЖШРДПДЃЌШЫЖњЛљгкСНИіЙиМќвђЫиРДИажЊвєЦЕаХКХЃКЦЕТЪКЭЩљбЙМЖЁЃЩљбЙМЖЃЈSPLЃЉвдЗжБДЃЈdBSPLЃЉЮЊЕЅЮЛЃЌБэЪОЮЇШЦЛЗОГДѓЦјбЙеёЕДЕФЩљбЙЗљЖШЁЃ100dBSPLЕФЩљбЙМЖЯрЕБгкИюВнЛњЛђжБЩ§ЛњЗЂГіЕФОоДѓдывєЁЃЩљбЙМЖЗЖЮЇФкЕФзюЕЭЕуЃЈ0dBЃЉЕШаЇгк20µPaЕФЩљбЙеёЕДЃЌетДњБэОпгазюМбЬ§СІЕФНЁПЕФъЧсШЫдк1kHzЦЕТЪЯТЕФЬ§СІуажЕЁЃЫљгагыгябдгаЙиЕФШЫРрЩљвєЖМЪєгк100HzжС8kHzЕФЦЕЖЮЁЃИљОнISO 226:2023 БъзМЃЌЯргІЕФШЫРрЬ§СІуажЕШчЭМ1ЫљЪОЁЃ
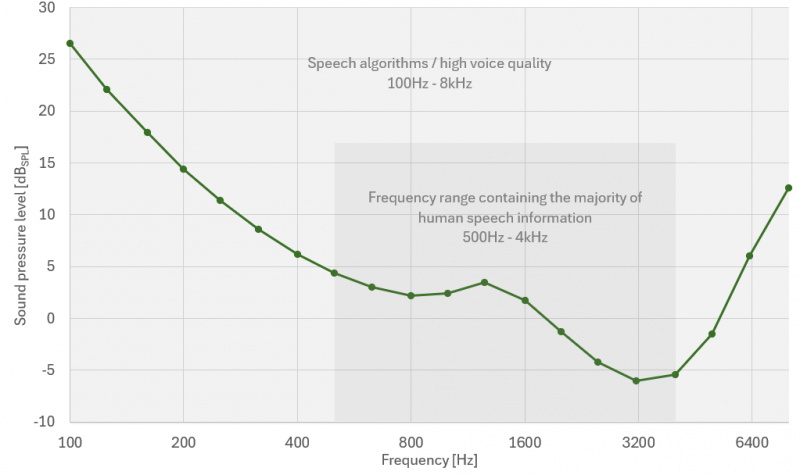
ЭМ1:Ь§СІуажЕЃКИљОнISO 226:2023ЃЌШЫдкжиИДЪдбщжазіГі 50%е§ШЗМьВтЗДгІЕФЩљМЖ
ШчЭМ1ЫљЪОШЫЖњЖд 500HzжС6kHz ЗЖЮЇФкЕФЦЕТЪЬиБ№УєИаЁЃетаЉЦЕТЪЩЯЕФШЮКЮЦЕТЪЦНКтЮЪЬтЖМЛсЖдЩљвєКЭРжЦїЕФИажЊжЪСПВњЩњжиДѓгАЯьЁЃ500HzжС4kHz жЎМфЕФЦЕТЪАќКЌСЫШЫРргявєжагАЯьгявєЧхЮњЖШЕФДѓВПЗжаХЯЂЁЃОпЬхРДЫЕЃЌ2 kHz зѓгвЕФЦЕТЪгШЮЊживЊЁЃ5kHzжС10kHz ЕФЦЕТЪЖдвєРжЗЧГЃживЊЁЃетаЉЦЕТЪЮЊЩљвєдіЬэСЫ "ЛюСІ "КЭ "ССЖШ"ЁЃШЛЖјЃЌетаЉЦЕТЪАќКЌЕФгявєаХЯЂЯрЖдНЯЩйЃЌжЛгапаЩљЃЌМД "zhi"ЁЂ"chi"КЭ "shi"ЕШДЪПЊЭЗЕФЫЛЫЛЩљЁЃНЕЕЭ 6-8kHzзѓгвЕФпаЩљЛсЖдгявєЧхЮњЖШВњЩњВЛРћгАЯьЁЃ
ЮвУЧДѓЖрЪ§ШЫЖМжЊЕРЃЌШЫРрЕФЬ§СІуажЕЛсЫцзХФъСфЕФдіГЄЖјЯТНЕЃЌШчЭМ 2 ЫљЪОЁЃ
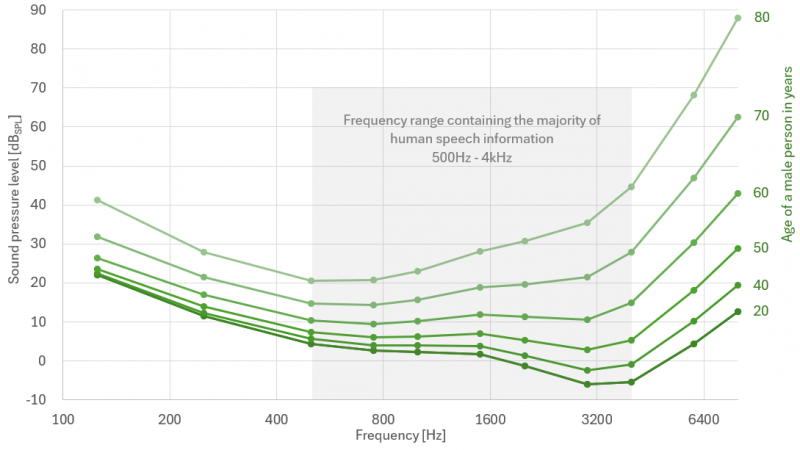
ЭМ 2: ИУЭМЯдЪОСЫВЛЭЌФъСфЖЮБОЬхе§ГЃЕФФааддкЕЅЩљЕРЖњЛњёіЬ§ЬѕМўЯТЕФЬ§уаЫЅМѕЧщПіЁЃЧызЂвтЃЌХЎадвВгаРрЫЦЕФЭМБэЃЌЦфЬ§СІЫЅМѕГЬЖШЫцФъСфдіГЄЖјТдгаНЕЕЭЃЈISO7029:2017ЃЉ
жЕЕУзЂвтЕФЪЧЃЌМДЪЙЪЧЧсЖШЬ§СІЫ№ЪЇЃЈДѓЖрЪ§ШЫЕФЬ§СІЫ№ЪЇЗЂЩњдк40жС50ЫъжЎМфЃЉвВЛсЖдИіШЫЩњЛюВњЩњжиДѓгАЯьЁЃР§ШчЃЌЛМгаЧсЖШЬ§СІЫ№ЪЇЕФШЫдкрадгЕФЛЗОГжаИњВЛЩЯМЏЬхЬИЛАПЩФмЛсгіЕНРЇФбЁЃДЫЭтЃЌЫћУЧЛЙПЩФмДэЙ§живЊЕФЬ§ОѕЬсЪОЃЌШчОЏИцаХКХЛђОЏБЈЁЃ
ФПЧАЕФвєЦЕгВМўЪЧЗёзувдТњзуЮДРДШЫЙЄжЧФмЕФашвЊЃП
МШШЛЮвУЧвбОЖдШЫРрШчКЮИажЊвєЦЕаХКХгаСЫИќКУЕФСЫНтЃЌФЧУДШУЮвУЧжиаТЩѓЪгвЛЯТзюГѕЕФЮЪЬтЃЌМДЕБЧАКЭЮДРДЕФШЫЙЄжЧФмашвЊЪВУДбљЕФвєЦЕЪфШыжЪСПЃЌВХФмДяЕНгыШЫРрЮовьЕФЫЎЦНЁЃ
ФПЧАЪаГЁЩЯЕФДѓЖрЪ§ЯћЗбРрЩшБИЖМЪЙгУMEMSТѓПЫЗчМЧТМвєЦЕаХКХЁЃMEMS ТѓПЫЗчЪЧШЫЙЄжЧФмИіШЫжњРэЕФжївЊвєЦЕВЖзНММЪѕЃЌЪЙгУШЫЙЄжЧФмжњРэММЪѕЕФЩшБИФПЧАвбПЊЪМдкЪаГЁЩЯЯњЪлЁЃ
MEMS ТѓПЫЗчЕФТМвєжЪСПШЁОігкЦфЖЏЬЌЗЖЮЇЃЈdynamic rangeЃЉЁЃЖЏЬЌЗЖЮЇЕФЩЯЯогЩЩљбЇЙ§диЕу (AOP) ШЗЖЈЃЌЫќЖЈвхСЫТѓПЫЗчдкИпЩљбЙМЖЪБЕФЪЇецадФмЁЃТѓПЫЗчЕФзддыЩљШЗЖЈСЫЦфЖЏЬЌЗЖЮЇЕФЯТЯоЁЃКтСПТѓПЫЗчзддыЩљЕФЗНЗЈЪЧаХдыБШ(SNR)ЃЌЫќЖЈвхСЫТѓПЫЗчЕФзддыЩљгыЦфВЖЛёЕФаХКХ(СщУєЖШ)жЎМфЕФБШТЪЁЃВЛЙ§ЃЌОЭЮвУЧЕФЬжТлЖјбдЃЌаХдыБШгааЉВЛКЯЪЪЃЌвђЮЊаХдыБШЕФзддыЩљЪЙгУСЫAМЦШЈЃЈA-weightingЃЉЃЌЖјAМЦШЈЦфЪЕЪЧЛљгкШЫРрИажЊвєЦЕаХКХЕФФмСІРДЖЈвхЕФЁЃ
ШчЙћвєЦЕаХКХЕФдЄЦкНгЪеепЪЧШЫЙЄжЧФмЃЌдђЯрЙиЕФТѓПЫЗчЕФЕШаЇдыЩљМЖENLЃЈequivalent noise levelЃЉЪЧКтСПадФмЕФИќКЯЪЪВЮЪ§ЃЌвђЮЊЫќКіТдСЫТМжЦЩљвєЕФШЫРрИажЊвђЫиЁЃЕШаЇдыЩљМЖENLжИЕФЪЧдкУЛгаЭтВПЩљдДЕФЧщПіЯТТѓПЫЗчВњЩњЕФаХКХЁЃЕШаЇдыЩљМЖENLвдЗжБДЃЈdBSPLЃЉЮЊЕЅЮЛЃЌБэЪОгыТѓПЫЗчзддыЩљЯрЭЌЕчбЙЕФЩљбЙМЖЁЃ
жЕЕУзЂвтЕФЪЧЃЌЮоТлКѓЦкВЩгУКЮжжЩљвєДІРэЗНЗЈЃЌЕЭгкЕШаЇдыЩљМЖENLЕФШЮКЮЩљвєаХЯЂЛљБОЩЯЖМЛсЖЊЪЇЃЌЮоЗЈЛжИДЁЃвђДЫЃЌШчЙћвєЦЕСДТЗжаУЛгаЦфЫћдЊМўдкаХКХЕНДяШЫЙЄжЧФмЫуЗЈжЎЧАв§ШыдывєЃЌТѓПЫЗчENLОЭПЩвдБЛЪгЮЊШЫЙЄжЧФмЫуЗЈЕФЬ§ОѕуажЕЁЃгІИУзЂвтЕФЪЧЃЌетЪЧвЛИіИпЖШМђЛЏЕФМйЩшЃЌвђЮЊвєЦЕСДжаЭЈГЃЛЙгааэЖрЦфЫћзщМўЃЌАќРЈЩљЕРЁЂЗРЫЎБЃЛЄФЄКЭвєЦЕДІРэСДТЗЁЃ
ЧыВЮПМЭМ 3СНжжMEMSТѓПЫЗчЕШаЇдыЩљМЖENLЧњЯпгыШЫРрЬ§СІуажЕЕФжБЙлЖдБШЁЃ
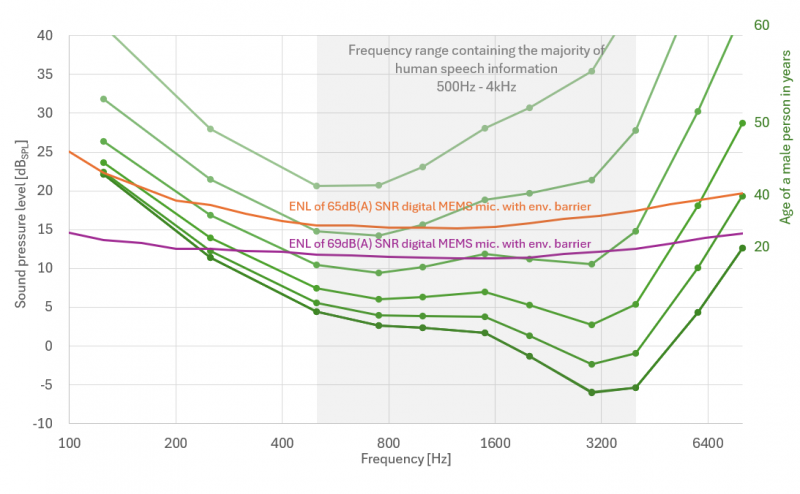
ЭМ 3:жаЖЫКЭИпЖЫMEMSТѓПЫЗчЕФ1/3БЖЦЕГЬЕШаЇдыЩљМЖENLгыЕфаЭФаадЬ§СІуажЕЕФБШНЯ
КьЩЋЯпЬѕЕФЪЧаХдыБШЮЊ65dB(A)ЕФТѓПЫЗчЕФЕШаЇдыЩљМЖENLЧњЯпЃЌТѓПЫЗчМЏГЩСЫЗРГОЩшМЦЁЃЯргІЕФMEMSТѓПЫЗчФПЧАвбгУгкЖрМвЙЉгІЩЬЩњВњЕФЖрПюИпЖЫжЧФмЪжЛњжаЁЃ
ЯТУцЕФзЯЩЋЯпЬѕБэЪОгЂЗЩСшзюаТИпЖЫЪ§зжТѓПЫЗчЕФЕШаЇдыЩљМЖENLЧњЯпЃЌИУТѓПЫЗчОпгаДДаТЕФЗРЛЄЩшМЦЃЌПЩЪЕЯжЗРГОЗРЫЎаЇЙћЁЃетПюТѓПЫЗчДњБэСЫЕБЧАЕФММЪѕЫЎЦНЃЌНёФъВХдкИпЖЫЦНАхЕчФдЩЯЗЂВМЁЃЮвУЧдЄМЦЃЌЕННёФъФъЕзЃЌадФмЯрЕБЕФТѓПЫЗчНЋГіЯждкИпЖЫжЧФмЪжЛњЩЯЁЃжЕЕУзЂвтЕФЪЧЃЌНЋТѓПЫЗчЕФзддыЩљНЕЕЭ 5-10dBЪЧвЛЯюжиДѓГЩОЭЃЌЬиБ№ЪЧПМТЧЕНЩљбЙЪЧЪЙгУЖдЪ§ПЬЖШРДБэЪОЕФЁЃ
ЫфШЛгЂЗЩСшдкНЕЕЭИпЖЫMEMSТѓПЫЗчЕФзддыЩљЗНУцШЁЕУСЫЯджјНјеЙЃЌЕЋгыШЫЖњЯрБШЃЌТѓПЫЗчдкБцБ№ЕЭЩљбЙМЖЕФФмСІЗНУцШдгаКмДѓВюОрЁЃгШЦфЪЧ2kHzИННќЃЌЖдгкШЗБЃШЫРрЬ§жкЛёЕУИпЫЎЦНЕФЩљвєЧхЮњЖШжСЙиживЊЁЃФъЧсШЫЕФЬ§ОѕФмСІгыгЂЗЩСшзюЯШНјЕФТѓПЫЗчжЎМфЕФВюОрГЌЙ§12dBSPLЁЃгыФПЧАИпЖЫЪжЛњжаЪЙгУЕФТѓПЫЗчЯрБШЃЌВюОрУїЯдИќДѓЃЌДяЕН17dBSPLЁЃашвЊдйДЮжИГіЕФЪЧЃЌетвЛЦРЙРНіПМТЧСЫMEMSТѓПЫЗчЕФзддыЩљЃЌВЂЮДПМТЧвєЦЕСДжаЛсНјвЛВННЕЕЭећЬхадФмЕФЖюЭтдыЩљдДЁЃ
ФПЧАMEMSТѓПЫЗчММЪѕЕФОжЯоаддкАќКЌДѓВПЗжШЫРргявєаХЯЂЕФЦЕТЪЗЖЮЇЃЈ500Hz - 4kHzЃЉФкзюЮЊУїЯдЁЃМДЪЙЪЧЪаГЁЩЯзюЯШНјЕФMEMSТѓПЫЗчЃЌЦфЩљвєРэНтФмСІвВжЛФмДяЕН60ЫъРЯШЫЕФЫЎЦНЁЃИљОнЯжгаЪ§ОнЃЌПЩвдКЯРэЕидЄМЦЃЌЪЙгУзюаТMEMSТѓПЫЗчММЪѕЕФШЫЙЄжЧФмащФтжњЪжНЋГіЯжгыРЯФъШЫРрЫЦЕФЬ§СІеЯАЃЌЬиБ№ЪЧдкашвЊдкрадгЛЗОГжаЛђдЖОрРыИњЖСЖдЛАЕФЧщПіЯТЁЃ
змНсгыеЙЭћ
ШЫЙЄжЧФмЕФЗЩЫйЗЂеЙВЛНіВЛЛсМѕЛКЃЌЗДЖјЛсМгЫйMEMSТѓПЫЗчЯђИќИпаХдыБШЗЂеЙЕФЧїЪЦЁЃЫфШЛзюаТЕФMEMSТѓПЫЗчЛЙЮоЗЈгыШЫЖњЕФвєЦЕжЪСПЯрцЧУРЃЌЕЋгЂЗЩСшдкНЕЕЭТѓПЫЗчзддыЩљЗНУцШЁЕУЕФНјеЙгаРћгкЯжгаКЭЮДРДЕФШЫЙЄжЧФмЁЃНјвЛВНИФНјвєЦЕСДТЗНЋЪЧдіЧПШЫЙЄжЧФмФмСІЕФЙиМќЃЌР§ШчжмЮЇЛЗОГЗжБцЁЂгяОГРэНтЁЂЧщИавтЪЖЁЂЫЕЛАепЪЖБ№КЭЖрШЫЖдЛАМЧТМЁЃгаСЫИќКУЕФвєЦЕЪфШыЃЌШЫЙЄжЧФмгыШЫРрЕФЛЅЖЏЗНЪННЋФмгыШЫРржЎМфЕФЛЅЖЏЯрЦЅХфЃЌЩѕжСВЛЯрЩЯЯТЁЃ
ДЫЭтЃЌШЫЛњНЛЛЅЫЎЦНЕФЬсИпНЋДйГЩаТЕФЛљгкШЫЙЄжЧФмЕФгУР§КЭЗўЮёЁЃР§ШчЃЌЯыЯѓвЛЯТЮДРДЕФЮЂШэCopilotЃЌЫќВЛНіФмзмНсЭХЖгЛсвщФкШнЃЌЛЙФмЬсЙЉЖдНЛЬИЗеЮЇЕФећЬхЦРЙРЁЃЮДРДЕФШЫЙЄжЧФмИЈжњЙІФмЛђаэПЩвдЛљгкШЫРрЕФгявєКЭвєЦЕЃЌЭЛГіЯдЪОжиЕуЛђАДееживЊадНјааХХађЁЃДЫЭтЃЌЛЙПЩвдЬэМгИЈЕМЙІФмЃЌЮЊгУЛЇЬсЙЉгагУЕФНЈвщЃЌАяжњЫћУЧИќКУЕиНЋЮДРДЕФЖдЛАв§ЯђЫљашЕФЗНЯђЁЃ
ЪдЯывЛЯТЃЌШЫЙЄжЧФмПЩвдЖдаТЕФЧѓжАепНјааЕквЛТжУцЪдЃЌЛђепНіЦОвєЦЕОЭФмЪЖБ№ЫЕЛАепЃЌЦфАВШЋМЖБ№зувдТњзуЭјЩЯЙКЮяЕФашвЊЁЃ
ЫљгаетаЉПЩФмжЛЪЧЮДРДШЫЙЄжЧФмЕФвЛаЁВПЗжЃЌЮДРДШЫЙЄжЧФмЕФЬ§СІФмСІНЋДяЕНЛђГЌЙ§ШЫРрЁЃЦОНшЮвУЧЕФдіЧПаЭ MEMSТѓПЫЗчНтОіЗНАИЃЌгЂЗЩСшКмШйавФмЙЛВЮгыетвЛМЄЖЏШЫаФЕФТУГЬЁЃ












