在之前,Cerebras用单个晶圆做了个芯片,这引起了广泛讨论。因为构建这些巨大的未来机器站点的概念证明很有可能为某些最苛刻的计算环境中的下一步做好准备。
但从通用的角度来看,这似乎又有点不切实际。
目前的选择也似乎是乘着摩尔定律的衰落或登上量子计算列车。第一个是不可避免的。第二个远非通用目的,特别是对于拥有数十年之久的核和其他关键任务模拟代码库的最大政府实验室而言,这些模拟是为传统计算量身定制的。
但实际上有一条中间路线。虽然它有它的挑战和它自己的扩展限制,但它可以将超级计算的性能在未来很长一段时间内持续提升,同时世界(表面上)为实际量子或任何真正的下一个方案做好准备。
这就是为什么这个中间选项,一个超异构、可定制的晶圆级平台有意义。让我们从技术和市场的角度来看:
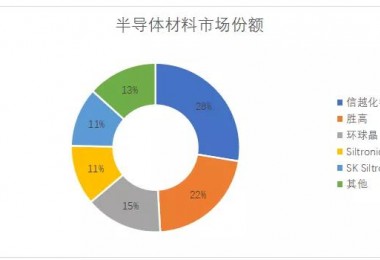
在市场方面,世界在很大程度上要归功于 AI 系统初创公司 Cerebras,因为它不仅重新引入了晶圆级的概念,而且还证明了它们可以工作。其实这个概念并不新鲜,早在 1980 年代它就是一个热门话题,并在 90 年代重新出现。但因为在这么多晶体管(当时)中出现故障太常见了,因此开发者们在运行这些芯片时,产生了无用的挫败感。
市场基本原理也仅到此为止。Cerebras 专注于人工智能训练和推理,可以选择做一些我们在这里讨论的通用工作。但计算考量的是数字上的能力,SRAM 很小并且在内核之间共享。它非常适合 AI,但对于有能力投资、试验和围绕新晶圆级构建的 HPC 而言,则不那么完美。这就是技术准备就绪的地方。
Cerebras 已经证明这是可以做到的,并且有一些客户愿意看一看(主要是国家实验室),但他们没有证明,在所有大型计算中,互连是使用晶圆级芯片的最大瓶颈,这也是释放主流潜力的关键。另一方面,AMD 正在证明小芯片方法是持续扩展的最有希望的途径。在其他方面,英特尔、IBM 和 AMD 也在展示互连级别的可能性。
那么为什么不把这些东西放在一起,构建一个可以利用小芯片实现超异构的晶圆级互连,创建大型系统来消除最紧迫的瓶颈,达成增加可扩展性和可定制性的方案呢?这样的话就可以使底层的晶圆级互连开放标准,以便所有可能的小芯片或(小芯片)都可以参与其中,包括大小处理器、DRAM、HBM,所有配置都可以适合工作负载。
当然,这不会便宜。但是,在量子计算上押下 10 亿美元的赌注不也是为了在后摩尔定律时代有所期待?
随着主要供应商致力于从 EMIB 到 AMD 的小芯片战略,这些都是有可能实现的。现在,有一些开创性的工作表明,从设计、可靠性和可制造性的角度来看,这一切都是实用的。
2015 年,加州大学洛杉矶分校的 Saptadeep Pal 与一个团队合作研究晶圆级的概念。这发生在 Cerebras 出现,并向市场证明他们的方案是有效之前。Pal 告诉 The Next Platform,他的团队中的一些人飞到圣何塞与 Andrew Feldman 和 Cerebras 团队会面,但他们没有交换技术,只是交谈。
“主要想法是构建一个具有许多核心的系统。不仅仅是计算核心;内存和不同类型的内存都紧密互连,不像今天的系统,而是通过在晶圆上构建互连。”
Pal 说,过去,晶圆级因为晶体管故障而被驳回,但答案根本不是构建晶体管,而是创建互连,然后采用可以单独构建和测试的普通芯片,获取已知好的芯片来自不同来源(处理器、DRAM、闪存等)的数据,并将它们打包到晶圆级互连中,以捕捉所有世界中最好的东西。“在晶圆上,我们已经知道如何构建元层。我们可以看到如何将这些小芯片连接到晶圆上以获得真正的异质晶圆,这是我们 2015 年的起点。”
强调 Cerebras 所做的与 Pal 和团队提出的建议之间的差异对于此类设备的特定与主流未来很重要。
从物理上讲,Cerebras 正在构建一个带有连接数千个内核的晶体管的晶圆。Pal 的团队正在做的是从不同来源获取芯片,将它们放在互连晶圆上,然后互连芯片。这导致密度相同,但异质性更大。
“Cerebras 所做的对于 ML 来说非常有用,在一个晶圆上有如此多的内核,而所有的小 SRAM 都连接在一个网状网络中。每几个内核共享一些 SRAM。但是我们正在采用这么多不同的芯片,现在每个芯片上的 Arm 内核和 DRAM 作为许多可能的实验之一,现在我们可以拥有具有 100k 或 200k 内核和 TB 内存的晶圆。这些存储器可以堆叠以提高密度,例如,我们可以在晶圆上看到每毫米边缘 1TB/s 的速度。”
我们需要考虑的事情是混合和匹配的可能性。适用于 HPC 的强劲 X86 内核、适用于特定工作负载的加速器、堆叠内存、高密度。选择是无穷无尽的。“而 Cerebras 通过展示如何为这些设备供电和冷却方面,确实做了令人印象深刻的工作。”
尽管 Pal 和团队取得了成功,并且 Cerebras 解决了制造/市场/可靠性问题,但将其推入更广泛的 HPC 领域仍然存在一些广泛的挑战(因为它必须从那里开始)。软件挑战是其中一个方面。另外,此类设备上可能的芯片组合数量如此之多,这可能会引致无穷无尽的问题,因此我们暂时不会为您解决这些问题。除了软件之外,仅在硬件方面将它们推向市场将需要更好的生态系统来测试小芯片的可靠性等。
“测试小芯片,将它们放在晶圆上,这样您就可以在键合后获得 99.9% 的成功?这绝对是一个挑战。但与此同时,因为我们是基于小芯片的,我们可以测试单独的设备,并且已经学会了一些技巧,可以在 Cerebras 必须在其架构中构建的冗余之外获得更高的信心。”
他说真正的困难在于,一旦拥有它,一切都非常昂贵,即使使用软件堆栈,您如何应对这个市场?“现在,我们只是在构建 Arm,我们还没有接触到编译器级别的东西。现在是让人们知道这种方案可以提供 100 倍以上性能,并给他们证明方案是否可靠。” 他补充说,人们对现在的系统构建方式感到满意。他们可以替换系统中的元素。有什么可以处理这样的系统上的故障,尤其是会影响整体功能的故障?
“系统越来越大;HPC 运行在数百个相距很远的节点上,互连就是瓶颈。我们需要一个统一的系统。将它们全部放在一块负责互连的硅片上就是答案。摩尔定律将发展到 2nm 或 1nm,而且成本也会很高。但是,正如 AMD 所展示的那样,转向小芯片是有效的。也显示了用晶圆级扩展它。找到一个今天每个人都可以接受的通用软件堆栈是我们接下来将首先使用 X86 和 Arm 做的事情,”Pal 补充道。
伊利诺伊大学与 Pal 的晶圆级合作伙伴 Rakesh Kumar 补充说:“基于小芯片的方法允许在晶圆上进行异构技术集成。这意味着基于小芯片的晶圆级处理器可以将高密度存储器(例如 DRAM、闪存等)驻留在同一处理器上。与无法在处理器上支持异构技术的 Cerebras 方法相比,这可以实现更好的内存容量特性,从而限制了处理器的内存容量。这对于许多应用程序(包括许多 ML 模型)来说至关重要,其应用程序要求远远超过 Cerebras 处理器提供的要求。
正如 Kumar 解释的那样,“基于小芯片的晶圆级处理器也可能具有良率优势,因为与 Cerebras 方法不同,不需要制造大型单片芯片。”
AMD 在构建这些方面处于有利地位。英特尔和 IBM 也可以做到。Cerebras 展示了一家初创公司也可以设法实现这一目标,但无法进入任何大市场或获得美国能源部的大型交易,如果可以展示后摩尔时代的能力,这些交易将在那里进行。有需求,有能力,有制造和市场的角度。
时机恰到好处,与超级计算等领域的量子不同,这些部分都具有让代码运行的已知机制。归根结底,这就是后百亿亿级/后摩尔的 HPC 领域所需要的答案。