国外媒体今天撰文指出,近年来人工智能(AI)取得了飞速发展,谷歌、Facebook和微软等科技巨头在语音和图像识别等AI领域都获得了重大突破,甚至有人认为我们正生活在一个“以AI为先”的时代。但是,在AI的前进道路上,目前仍然有三个巨大的障碍需要跨越。以下为文章全文:
在上个月于伦敦举行的深度学习大会上,有一个特别值得关注的主题:谦卑,或者说需要谦卑。
包括谷歌在内的许多公司都信誓旦旦地宣称,我们正生活在一个“以AI为先的时代”,机器学习也在语音和图像识别等领域取得了突破,但是身在AI研究最前沿的人经常指出,人类在这方面仍有大量工作要做。仅仅因为我们拥有了听上去像电影中会说话的虚拟助手,并不意味着我们距离创造真正的人工智能更近一步。
我们在人工智能研究领域还面临着诸多挑战,比如需要海量数据来支持深度学习系统;我们还不能打造出不止擅长一项任务的AI;我们对这些系统的工作原理缺乏认识。2016年,机器学习创造了一系列极为出色的工具,但这些工具难以具体解释,训练费用高昂,即便对创造者来说,它们往往也像是谜一般的存在。下面就让我们来详细阐述一下我们在人工智能领域面临的三大挑战。
数据、数据,还是数据
众所周知,人工智能需要数据来了解世界,但我们往往会忽视数据多少的重要性。英国谢菲尔德大学机器学习教授、亚马逊人工智能团队成员尼尔·劳伦斯(Neil Lawrence)指出,若想理解概念或识别某项功能,这些系统不仅需要比人类更多 的信息,而且需要的信息数量更是多出人类数十万倍。
劳伦斯说:“如果你看一看深度学习在哪些领域的应用取得了成功,那么会发现这些往往是我们需要大量数据的领域。”例如,在语音和图像识别领域,谷歌和Facebook等科技巨头都拥有海量数据(如安卓设备上的语音搜索),令他们可以轻松开发有用的工具。
劳伦斯称,当前,数据就像是工业革命早期的煤炭。他还以汤玛斯·纽科门(Thomas Newcomen)为例来说明这一点。纽科门是英国人,在1712年发明了以煤为燃料的原始蒸汽机,比詹姆斯·瓦特(James Watt)发明先进蒸汽机早了大概60年。纽科门发明的蒸汽机并不太好,相比瓦特蒸汽机,效率低,费用高。这意味着,它只能在煤田使用——煤田有足够多的燃料来克服蒸汽机的诸多不利条件。

国外媒体今天撰文指出,近年来人工智能(AI)取得了飞速发展,谷歌、Facebook和微软等科技巨头在语音和图像识别等AI领域都获得了重大突破,甚至有人认为我们正生活在一个“以AI为先”的时代。但是,在AI的前进道路上,目前仍然有三个巨大的障碍需要跨越。以下为文章全文:
在上个月于伦敦举行的深度学习大会上,有一个特别值得关注的主题:谦卑,或者说需要谦卑。
包 括谷歌在内的许多公司都信誓旦旦地宣称,我们正生活在一个“以AI为先的时代”,机器学习也在语音和图像识别等领域取得了突破,但是身在AI研究最前沿的人经常指出,人类在这方面仍有大量工作要做。仅仅因为我们拥有了听上去像电影中会说话的虚拟助手,并不意味着我们距离创造真正的人工智能更近一步。
我们在人工智能研究领域还面临着诸多挑战,比如需要海量数据来支持深度学习系统;我们还不能打造出不止擅长一项任务的AI;我们对这些系统的工作原理缺乏认识。2016年,机器学习创造了一系列极为出色的工具,但这些工具难以具体解释,训练费用高昂,即便对创造者来说,它们往往也像是谜一般的存在。下面就让我们来详细阐述一下我们在人工智能领域面临的三大挑战。
数据、数据,还是数据
众所周知,人工智能需要数据来了解世界,但我们往往会忽视数据多少的重要性。英国谢菲尔德大学机器学习教授、亚马逊人工智能团队成员尼尔·劳伦斯(Neil Lawrence)指出,若想理解概念或识别某项功能,这些系统不仅需要比人类更多的信息,而且需要的信息数量更是多出人类数十万倍。
劳伦斯说:“如果你看一看深度学习在哪些领域的应用取得了成功,那么会发现这些往往是我们需要大量数据的领域。”例如,在语音和图像识别领域,谷歌和Facebook等科技巨头都拥有海量数据(如安卓设备上的语音搜索),令他们可以轻松开发有用的工具。
劳伦斯称,当前,数据就像是工业革命早期的煤炭。他还以汤玛斯·纽科门(Thomas Newcomen)为例来说明这一点。纽科门是英国人,在1712年发明了以煤为燃料的原始蒸汽机,比詹姆斯·瓦特(James Watt)发明先进蒸汽机早了大概60年。纽科门发明的蒸汽机并不太好,相比瓦特蒸汽机,效率低,费用高。这意味着,它只能在煤田使用——煤田有足够多的燃料来克服蒸汽机的诸多不利条件。
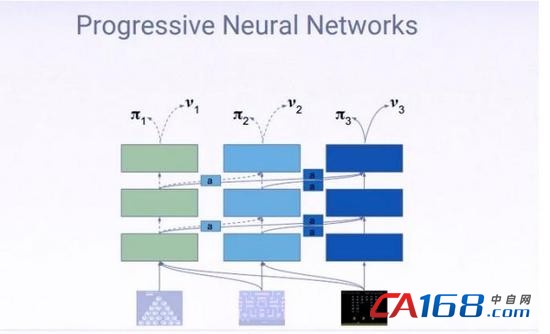
这是一种颇具前景的方法,在最新实验中,它甚至可以应用于机械臂——将机械臂的学习过程从过去的几周,缩短为现在的一天。然而,这种方法也存在诸多严重的短板,哈德塞尔称渐进神经网络不能持续地在“记忆”中增加新任务。她说,如果你将几条铁链子连在一起,那么整条链子迟早“变得过于庞大,难以驾驭”。到那个时候,我们正在管理的不同任务基本上都是相同的——打造一种智力相当于人类的系统,可以写诗、解决微分方程、设计椅子,这种系统也将成为与众不同的东西。
缺乏对AI内部机制的了解
另一个重大挑战是,理解人工智能如何得出它们的结论。对于外行人来说,神经系统通常是谜一般的存在。虽然我们了解了如何将它们连接起来的办法,也了解了经过这些系统的信息,但这些系统为何会作出某些决定,原因往往是我们难以理解的。
弗吉尼亚理工学院的一次实验,就充分展现了这一挑战。研究人员给神经网络开发了一种眼部追踪系统,将计算机最先看到的像素记录下来。研究人员将一张卧室的神经网络照片拿给该系统看,然后问:“盖住窗户的是什么东西?”他们发现,该系统并没有看窗户,而是朝地上看了看。
接着,如果发现了一张床,它会回答“窗帘盖住了窗户”。该系统碰巧给出了正确答案,但这只是因为它接受训练时的数据有限。根据研究人员向它展示的照片,神经网络得出了这样的一个结论,即如果是在卧室中,那么窗户上一定要窗帘。所以,只要看到床,该系统就不会再看第二眼了——它已经看到过窗帘了。当然,这合乎逻辑,但却是很愚蠢的做法。许多卧室根本就没有窗帘!
眼部追踪只是一个揭示AI内部机制的方法,另一个方法可能是给深度学习系统注入更多的连贯性。伦敦大学帝国理工学院认知机器人科学教授莫里·沙纳汉(Murray Shanahan)表示,实现这一目的的途径是,重新采用一种名为“有效的老式人工智能”( GOFAI)的传统机器学习方法。这种方法是基于一个假想提出的,即脑海中发生的东西可以缩减为基本的逻辑,让世界由众多复杂的符号来定义。通过将这些表示动作、事件和物体的符号结合起来,你基本上可以形成自己的看法。
沙纳汉建议,我们应该吸取GOFAI的符号描述方法,然后与深度学习结合起来。这些系统将成为人工智能系统了解世界的一个起点,而不是不断提供数据,等待其识别某些图像。他说,这种办法不仅可以解决AI的透明度问题,而且还能解决哈德塞尔提出的转移学习成果的问题。
沙纳汉说:“可以这样说,《Breakout》类似于《Pong》,因为它们都得到了桨和球,但堪比人类的认知能力将它们以更大的规模连接起来,就像是原子结构和太阳系结构之间的连接一样。”沙纳汉及其团队正在开发一种新的方法(他们称之为“深度符号增强学习法”),并且公布了一些实验成果。
这项研究目前仍然处于初级阶段,发现它是否可以应用于更大的系统和不同类型的数据,将更加具有说服力。但是,它很有可能会演变为更多的东西。毕竟,在研究人员近年来开始挖掘廉价数据和大量处理能力之前,深度学习本身就是AI当中一个不受垂青的部分。也许,现在到了AI迎来再一次爆发,在新环境下大展身手的时候了。